Hbase笔记
1.Hbase调优
- 高可用
在HBase中Hmaster负责监控RegionServer的生命周期,均衡RegionServer的负载,如果Hmaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对Hmaster的高可用配置。 - 预分区
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能。 - 优化RowKey设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个一个预分区的区间内,设计rowkey的主要目的,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜 - 内存优化
HBase操作过程中需要大量的内存开销,毕竟Table是可以缓存在内存中的,一般会分配整个可用内存的70%给HBase的Java堆。但是不建议分配非常大的堆内存,因为GC过程持续太久会导致RegionServer处于长期不可用状态,一般16~48G内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
2.hbase的rowkey怎么创建好?列族怎么创建比较好?
hbase存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
一个列族在数据底层是一个文件,所以将经常一起查询的列放到一个列族中,列族尽量少,减少文件的寻址时间。
设计原则
1)rowkey 长度原则
2)rowkey 散列原则
3)rowkey 唯一原则
如何设计
1)生成随机数、hash、散列值
2)字符串反转
3) 字符串拼接
3.hbase过滤器实现用途
增强hbase查询数据的功能
减少服务端返回给客户端的数据量
4.HBase宕机如何处理
答:宕机分为HMaster宕机和HRegisoner宕机,如果是HRegisoner宕机,HMaster会将其所管理的region重新分布到其他活动的RegionServer上,由于数据和日志都持久在HDFS中,该操作不会导致数据丢失。所以数据的一致性和安全性是有保障的。
如果是HMaster宕机,HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行。即ZooKeeper会保证总会有一个HMaster在对外提供服务。
5.hive跟hbase的区别是?
共同点:
1.hbase与hive都是架构在hadoop之上的。都是用hadoop作为底层存储
区别:
2.Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
3.想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop 。
4.Hive query就是MapReduce jobs可以从5分钟到数小时不止,HBase是非常高效的,肯定比Hive高效的多。
5.Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。
6.hive借用hadoop的MapReduce来完成一些hive中的命令的执行
7.hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
8.hbase是列存储。
9.hdfs作为底层存储,hdfs是存放文件的系统,而Hbase负责组织文件。
10.hive需要用到hdfs存储文件,需要用到MapReduce计算框架。
6.hbase写流程
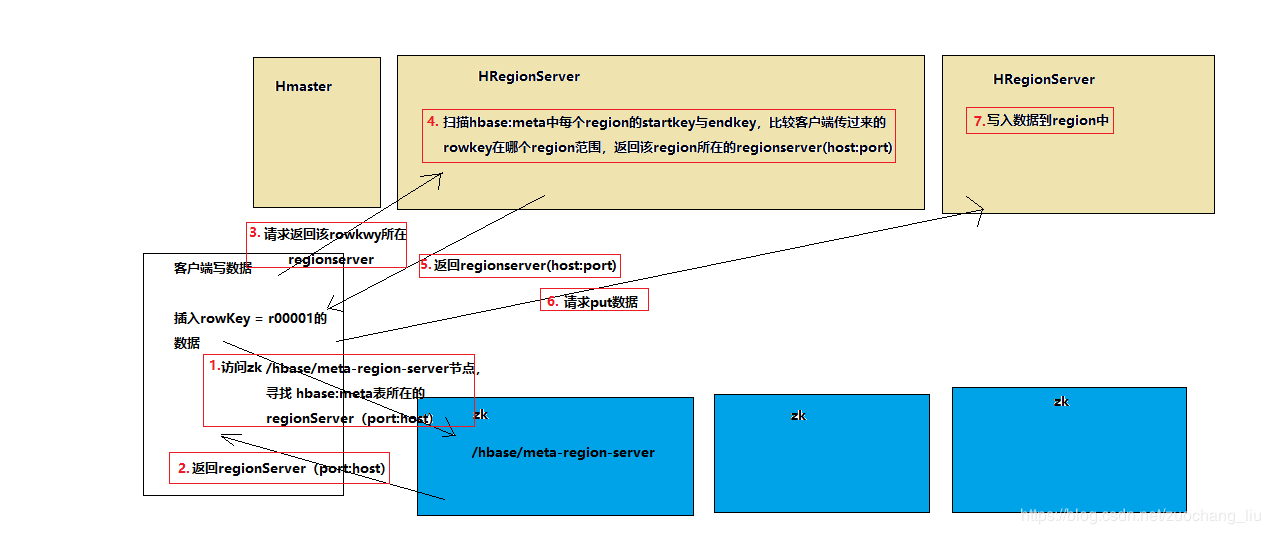
- 客户端要连接zookeeper, 从zk的/hbase节点找到hbase:meta表所在的regionserver(host:port);
- regionserver扫描hbase:meta中的每个region的起始行健,对比r000001这条数据在那个region的范围内;
- 从对应的 info:server key中存储了region是有哪个regionserver(host:port)在负责的;
- 客户端直接请求对应的regionserver;
- regionserver接收到客户端发来的请求之后,就会将数据写入到region中
7.hbase读流程
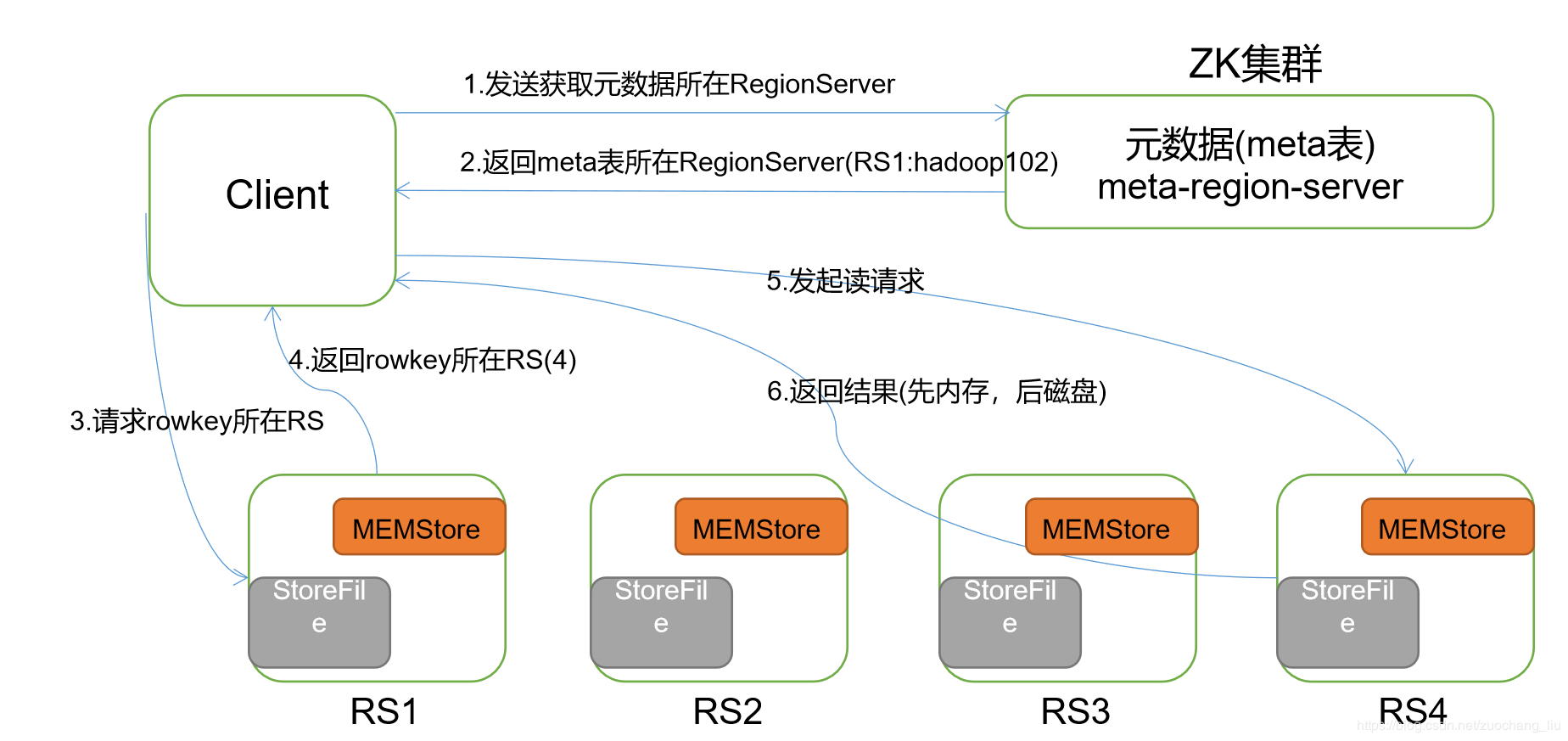
- 首先Client连接zookeeper, 找到hbase:meta表所在的regionserver;
- 请求对应的regionserver,扫描hbase:meta表,根据namespace、表名和rowkey在meta表中找到r00001所在的region是由那个regionserver负责的;
- 找到这个region对应的regionserver
- regionserver收到了请求之后,扫描对应的region返回数据到Client
(先从MemStore找数据,如果没有,再到BlockCache里面读;BlockCache还没有,再到StoreFile上读(为了读取的效率);
如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端。)
8.hbase数据flush过程
- 当MemStore数据达到阈值(默认是128M,老版本是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据;
- 并将数据存储到HDFS中;
- 在HLog中做标记点。
9.数据合并过程
- 当数据块达到4块,hmaster将数据块加载到本地,进行合并
- 当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的hregionserver管理
- 当hregionser宕机后,将hregionserver上的hlog拆分,然后分配给不同的hregionserver加载,修改.META.
- 注意:hlog会同步到hdfs
10.Hmaster和HRgionserver职责
Hmaster
1、管理用户对Table的增、删、改、查操作;
2、记录region在哪台Hregion server上
3、在Region Split后,负责新Region的分配;
4、新机器加入时,管理HRegion Server的负载均衡,调整Region分布
5、在HRegion Server宕机后,负责失效HRegion Server 上的Regions迁移。
HRegion server
- HRegion Server主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBASE中最核心的模块。
- HRegion Server管理了很多table的分区,也就是region。
11.HBase列族和region的关系?
HBase有多个RegionServer,每个RegionServer里有多个Region,一个Region中存放着若干行的行键以及所对应的数据,一个列族是一个文件夹,如果经常要搜索整个一条数据,列族越少越好,如果只有一部分的数据需要经常被搜索,那么将经常搜索的建立一个列族,其他不常搜索的建立列族检索较快。
12.请简述Hbase的物理模型是什么
(1)Table在行的方向上分割为多个Region。
(2)Table中的所有行都按照row key的字典序排列,根据rowkey存储在不同的Region上。
(3)Region是按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阈值的时候,region就会等分成两个新的region,之后会有越来越多的region。
(4)Region是HBase中分布式存储和负载均衡的最小单元。不同Region分布到不同RegionServer上。移动的时候是移动一个Region,进行不同RegionServer之间的负载均衡。
(5)Region虽然是分布式存储的最小单元,但并不是存储的最小单元,存储的最小单元是Cell。Region由一个或者多个Store组成,每个store保存一个columns family列簇。每个store又由一个memStore和0至多个StoreFile组成。memStore存储在内存中,StoreFile存储在HDFS上。memStore是内存中划分的一个区间,StoreFile是底层存储在HDFS上的文件。
(6)每个column family存储在HDFS上的一个单独文件中。Key和Version number在每个column family中均有一份。空值不会被保存。
13.请问如果使用Hbase做即席查询,如何设计二级索引
1)索引与主数据存放在同一张表的不同Column Family 中
索引与主数据划分到同一个Region 上,从索引抓取目标主数据减少RPC 次数,减少网络通信压力,把性能损失降低到最小
索引与主数据分配在不同的Column Family 中,实现了索引与主数据的物理分离
2)索引区的Column Family 不包含任何 Qualifier,是一个典型的“Dummy Column Family”
减少读写压力,快速定位
3)RowKey 格式:RegionStartKey-索引名-索引键-索引值
RegionStartKey:索引RowKey 的前缀固定为当前Region的StartKey,一方面,这个值处在Region 的RowKey 区间之内,它确保了索引必定跟随其主数据被划分到同一个Region 里;另一方面,这个值是RowKey 区间内的最小值,这保证了在同一Region 里所有索引会集中排在主数据之前,实现了索引与主数据的逻辑分离。
索引键:由目标记录各对应字段的值组合而成
索引值:记录对应的RowKey
14.如何避免读、写HBaes时访问热点问题?
rowkey的散列或预分区
预分区一开始就预建好了一部分region,这些region都维护着自己的start-end keys,我们将rowkey做一些处理,比如RowKey%i,写数据能均衡的命中这些预建的region,就能解决上面的那些缺点,大大提供性能。
而将rowkey散列化就是避免rowkey自增,这样也能解决上面所说的缺点。
- rowkey前面加随机数
- 哈希
- 反转
- 使用反转的时间戳作为rowkey的一部分
15.布隆过滤器在HBASE中的应用
布隆过滤器的作用是,用户可以立即判断一个文件是否包含特定的行键,从而帮我们过滤掉一些不需要扫描的文件。
16.Hbase是用来干嘛的?什么样的数据会放到hbase
当我们对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用使用什么数据库?
最适合使用Hbase存储的数据是非常稀疏的数据(非结构化或者半结构化的数据)。Hbase之所以擅长存储这类数据,是因为Hbase是column-oriented列导向的存储机制,而我们熟知的RDBMS都是row- oriented行导向的存储机制(郁闷的是我看过N本关于关系数据库的介绍从来没有提到过row- oriented行导向存储这个概念)。在列导向的存储机制下对于Null值得存储是不占用任何空间的。比如,如果某个表 UserTable有10列,但在存储时只有一列有数据,那么其他空值的9列是不占用存储空间的(普通的数据库MySql是如何占用存储空间的呢?)。
Hbase适合存储非结构化的稀疏数据的另一原因是他对列集合 column families 处理机制。
现在Hbase为未来的DBA也带来了这个激动人心的特性,你只需要告诉你的数据存储到Hbase的那个column families 就可以了,不需要指定它的具体类型:char,varchar,int,tinyint,text等等。