flume、sqoop笔记
1.什么是flume
a.Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
b.Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka等众多外部存储系统中
c.一般的采集需求,通过对flume的简单配置即可实现
d.Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
2.flume运行机制
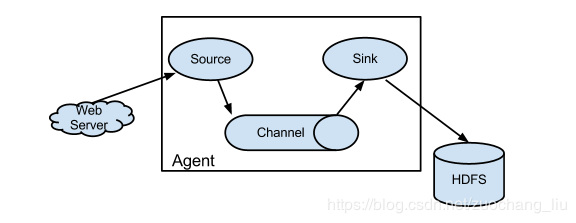
- Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
- 每一个agent相当于一个数据传递员,内部有三个组件:
- Source:采集源,用于跟数据源对接,以获取数据
- Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
- Channel:angent内部的数据传输通道,用于从source将数据传递到sink
3.Flume采集数据到Kafka中丢数据怎么办
Source到Channel是事务性的,
Channel到Sink也是事务性的,
这两个环节都不可能丢失数据。
唯一可能丢失数据的是Channel采用MemoryChannel.
4.Flume怎么进行监控?
Ganglia
5.Flume的三层架构,collector、agent、storage
Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
1)Agent层:这一层包含了Flume的Agent组件,与需要传输数据的数据源连接在一起
2)Collector:这一层通过多个收集器收集Agent层的数据,然后将这些转发到下一层
3)storage:这一层接收collector层的数据并存储起来
分割线———————————————————————————————————
1.Sqoop底层运行的任务是什么
只有Map阶段,没有Reduce阶段的任务。
2.Sqoop的迁移数据的原理
将导入或导出命令翻译成mapreduce程序来实现,在翻译出的mapreduce中主要是对inputformat和outputformat进行定制。
3.Sqoop参数
1 | /opt/module/sqoop/bin/sqoop import \ |
4.Sqoop导入导出Null存储一致性问题
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用–input-null-string和–input-null-non-string两个参数。导入数据时采用–null-string和–null-non-string。
5.Sqoop数据导出一致性问题
1)场景1:如Sqoop在导出到Mysql时,使用4个Map任务,过程中有2个任务失败,那此时MySQL中存储了另外两个Map任务导入的数据,此时老板正好看到了这个报表数据。而开发工程师发现任务失败后,会调试问题并最终将全部数据正确的导入MySQL,那后面老板再次看报表数据,发现本次看到的数据与之前的不一致,这在生产环境是不允许的。
2)场景2:设置map数量为1个(不推荐,面试官想要的答案不只这个)
多个Map任务时,采用–staging-table方式,仍然可以解决数据一致性问题。