Flink学习笔记
1.初识FLink
Flink是什么
Apache Flink是一个框架和分布式处理引擎,用于对无限制和有限制的数据流进行有状态的计算。Flink被设计为可在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
Unbounded data: 有头无尾
Bounded data: 有头有尾
==> 都可以使用flink来进行处理,对应的就是流处理和批处理
1 | Spark: Streaming 结构化流 批处理为主 |
2.快速上手开发第一个Flink应用程序
环境准备
JDK:
下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Mac :dmg
Linux: tar.gz
Windows: exe
Maven
官网:maven.apache.org
下载地址:https://archive.apache.org/dist/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz
Linux/Mac/Windows:解压
tar -zxvf apache-maven-3.3.9-bin.tar.gz -C ~/app
conf/setting.xml
<localRepository>/Users/rocky/maven_repos</localRepository>Flink开发批处理应用程序
需求:词频统计(word count)
一个文件,统计文件中每个单词出现的次数
分隔符是\t
统计结果我们直接打印在控制台(生产上肯定是Sink到目的地)
实现:
Flink + Java
前置条件: Maven 3.0.4 (or higher) and Java 8.x
第一种创建项目的方式:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.7.0 \
-DarchetypeCatalog=local
out of the box:OOTB 开箱即用
开发流程/开发八股文编程
1)set up the batch execution environment
2)read
3)transform operations 开发的核心所在:开发业务逻辑
4)execute program
功能拆解
1)读取数据
hello welcome
2)每一行的数据按照指定的分隔符拆分
hello
welcome
3)为每一个单词赋上次数为1
(hello,1)
(welcome,1)
4) 合并操作 groupBy
Flink + Scala
前置条件:Maven 3.0.4 (or higher) and Java 8.x
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-scala \
-DarchetypeVersion=1.7.0 \
-DarchetypeCatalog=local
Flink Java vs Scala
1) 算子 map filter
2)简洁性3.编程模型及核心概念
大数据处理的流程:
MapReduce:input -> map(reduce) -> output
Storm: input -> Spout/Bolt -> output
Spark: input -> transformation/action –> output
Flink: input -> transformation/sink –> output
DataSet and DataStream
immutable
批处理:DataSet
流处理:DataStream
Flink编程模型
1)获取执行环境
2)获取数据
3)transformation
4)sink
5)触发执行
select a., b. from a join b on a.id = b.id
<a1,(a.*)>
<b1,(b.*)>
4.DataSet API编程
5.DataStream API编程
6.Flink Table API & SQL编程
DataSet&DataStream API
1) 熟悉两套API:DataSet/DataStream Java/Scala
MapReduce ==> Hive SQL
Spark ==> Spark SQL
Flink ==> SQL
2) Flink是支持批处理/流处理,如何做到API层面的统一
==> Table & SQL API 关系型API
Everybody knows SQL
7.Flink中的Time及Windows的使用
对于Flink里面的三种时间
事件时间 10:30
摄取时间 11:00
处理时间 11:30
思考:
对于流处理来说,你们觉得应该是以哪个时间作为基准时间来进行业务逻辑的处理呢?
幂等性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
思考:默认的TimeCharacteristic是什么?
窗口分配器:定义如何将数据分配给窗口
A WindowAssigner is responsible for assigning each incoming element to one or more windows
每个传入的数据分配给一个或者多个窗口
tumbling windows 滚动窗口
have a fixed size and do not overlap
sliding windows 滑动窗口
overlapping 业务案例:每隔半小时,统计前一个小时的top n商品。
session windows 会话窗口
global windows 全局窗口
[start timestamp , end timestamp)
ReduceFunction: 两两进行处理
ProcessWindowFunction:整个窗口全部到了,再处理。场景:对窗口中的数据排序
https://blog.csdn.net/lmalds/article/details/52704170
8.Flink Connectors
ZooKeeper
https://archive.cloudera.com/cdh5/cdh/5/
ssh hadoop@192.168.199.233
1) 从~/software下解压到~/app目录下
2) 配置系统环境变量 ~/.bash_profile
3) 配置文件 $ZK_HOME/conf.zoo.cfg dataDir不要放在默认的/tmp下
4) 启动ZK $ZK_HOME/bin/zkServer.sh start
5) 检查是否启动成功 jps QuorumPeerMainKafka
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/1.1.1/kafka_2.11-1.1.1.tgz
ssh hadoop@192.168.199.233
1) 从~/software下解压到~/app目录下
2) 配置系统环境变量 ~/.bash_profile
3) 配置文件 $KAFKA_HOME/config/server.properties
log.dirs 不要放在默认的/tmp下
4) 启动Kafka$KAFKA_HOME/bin/kafka-server-start.sh -daemon /home/hadoop/app/kafka_2.11-1.1.1/config/server.properties
5) 检查是否启动成功 jps Kafka
6) 创建topic./kafka-topics.sh –create –zookeeper hadoop000:2181 –replication-factor 1 –partitions 1 –topic pktest
7) 查看所有的topic
./kafka-topics.sh –list –zookeeper hadoop000:2181
8) 启动生产者
./kafka-console-producer.sh –broker-list hadoop000:9092 –topic pktest
9) 启动消费者
./kafka-console-consumer.sh –bootstrap-server hadoop000:9092 –topic pktest
作业:请使用Java语言开发FlinkKafkaConsumer/FlinkKafkaProducer实例
9.Flink部署及作业提交
Flink的单机部署方式
开发/测试
前置条件:
JDK8
Maven3
通过下载Flink源码进行编译,不是使用直接下载二进制包
下载到:
1)服务器:~/source wget https://github.com/apache/flink/archive/release-1.7.0.tar.gz
2) 本地:https://github.com/apache/flink/archive/release-1.7.0.tar.gz
mvn clean install -DskipTests -Pvendor-repos -Dfast -Dhadoop.version=2.6.0-cdh5.15.1
第一次编译是需要花费很长时间的,因为需要去中央仓库下载flink源码中所有的依赖包
Standalone的最简单的方式
./bin/flink run examples/streaming/SocketWindowWordCount.jar –port 9000
./bin/flink # 路径 $FLINK_HOME
Standalone-分布式
1) Java 1.8.x or higher
2) ssh 多个机器之间要互通 Hadoop详细讲解
ping hadoop000
ping hadoop001
ping hadoop002
JDK
Flink 同一个目录 集群里面的机器 部署的目录都是一样
每个机器需要添加ip和hostname的映射关系3) conf
flink-conf.yaml
jobmanager.rpc.address: 10.0.0.1 配置主节点的ip
jobmanager 主节点
taskmanager 从节点
slaves
每一行配置一个ip/host4)常用配置
jobmanager.rpc.address master节点的地址
jobmanager.heap.mb jobmanager节点可用的内存
taskmanager.heap.mb taskmanager节点可用的内存
taskmanager.numberOfTaskSlots 每个机器可用的cpu个数
parallelism.default 任务的并行度
taskmanager.tmp.dirs taskmanager的临时数据存储目录
扩展或者容错
ON YARN是企业级用的最多的方式 *****
-n taskmanager的数量
-jm jobmanager的内存
-tm taskmanager的内存
./bin/flink run ./examples/batch/WordCount.jar
-input hdfs://hadoop000:8020/LICENSE-2.0.txt
-output hdfs://hadoop000:8020/wordcount-result.txt
./bin/flink run -m yarn-cluster -yn 1 ./examples/batch/WordCount.jar
作业:
1) 快速开发一个Flink应用程序
Scala&Java
批处理&流处理
批处理Scala和批处理Java的Flink作业提交到YARN上去执行,任意YARN模式
2)可选 HA的配置
https://ci.apache.org/projects/flink/flink-docs-release-1.7/ops/jobmanager_high_availability.html
10.Flink监控及调优
History Server
Hadoop MapReduce
Spark
Flink
start/stop-xxx.sh
看一下这些脚本的写法
shell对于bigdata有用吗? lower
配置:
historyserver.web.address: 0.0.0.0
historyserver.web.port: 8082
historyserver.archive.fs.refresh-interval: 10000
jobmanager.archive.fs.dir: hdfs://hadoop000:8020/completed-jobs-pk/
historyserver.archive.fs.dir: hdfs://hadoop000:8020/completed-jobs-pk/
启动:./historyserver.sh start
思考:有了HistoryServer之后为什么还需要提供REST API?
Ganglia
Flink中常用的优化策略
1)资源
2)并行度
默认是1 适当的调整:好几种 ==> 项目实战
3)数据倾斜
100task 98-99跑完了 1-2很慢 ==> 能跑完 、 跑不完
group by: 二次聚合
random_key + random
key - random
join on xxx=xxx
repartition-repartition strategy 大大
broadcast-forward strategy 大小
https://dzone.com/articles/four-ways-to-optimize-your-flink-applications
11.基于Flink的互联网直播平台日志分析项目实战
项目背景
aliyun CN A E [17/Jul/2018:17:07:50 +0800] 2 223.104.18.110 - 112.
29.213.35:80 0 v2.go2yd.com GET http://v1.go2yd.com/user_upload/1531633977627104fdec
dc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 HTTP/1.1 - bytes 13869056-13885439/25136186 TCP_HIT/206 112.29.213.35 video/mp4 17168 16384 -:0 0 0 - - 11451601 - “JSP3/2.0.14” “-“ “-“ “-“ http - 2 v1.g
o2yd.com 0.002 25136186 16384 - - - - - - - 1531818470104-114516
01-112.29.213.66#2705261172 644514568
aliyun
CN
E
[17/Jul/2018:17:07:50 +0800]
223.104.18.110
v2.go2yd.com
17168
接入的数据类型就是日志
离线:Flume==>HDFS
实时:Kafka==>流处理引擎==>ES==>Kibana
项目架构图
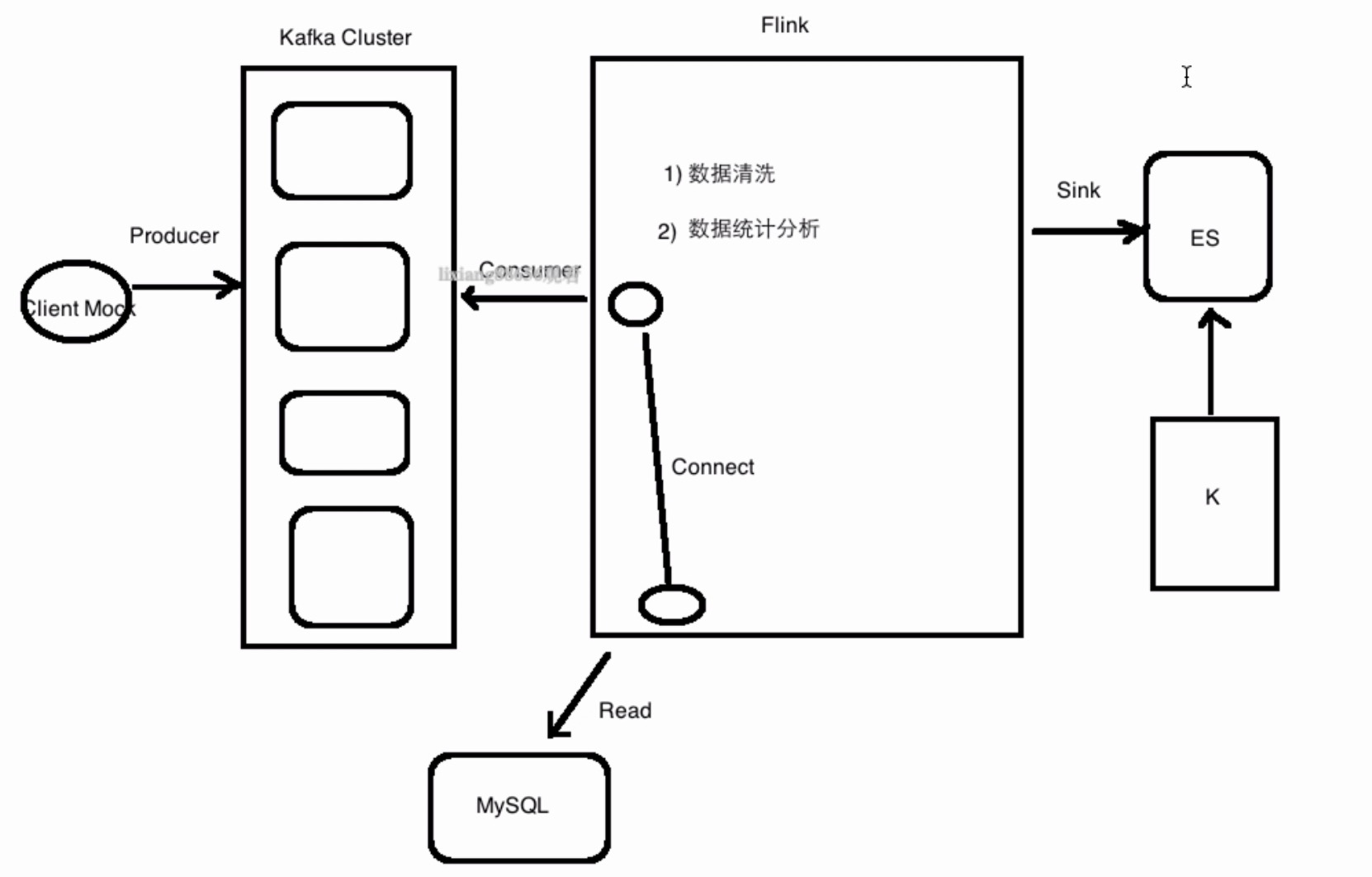
项目功能
1)统计一分钟内每个域名访问产生的流量
Flink接收Kafka的进行处理
2)统计一分钟内每个用户产生的流量
域名和用户是有对应关系的
Flink接收Kafka的进行 + Flink读取域名和用户的配置数据 进行处理
数据:Mock *****
Mock数据:务必要掌握的
数据敏感
多团队协作,你依赖了其他团队提供的服务或者接口
通过Mock的方式往Kafka的broker里面发送数据
Java/Scala Code:producer
kafka控制台消费者:consumer需求:最近一分钟每个域名对应的流量
问题:
可以到QQ群或者问答区进行交流,
我在群里的,
问答区的问题我会用最快的速度答疑
ES部署
1) CentOS7.x
2) 非root hadoop
ELK
Kibana部署
curl -XPUT ‘http://hadoop000:9200/cdn'
curl -H “Content-Type: application/json” -XPOST ‘http://hadoop000:9200/cdn/traffic/_mapping?pretty' -d ‘{
“traffic”:{
“properties”:{
“domain”:{“type”:”text”},
“traffics”:{“type”:”long”},
“time”:{“type”:”date”,”format”: “yyyy-MM-dd HH:mm”}
}
}
}
‘
curl -XDELETE ‘hadoop000:9200/cdn’
curl -H “Content-Type: application/json” -XPOST ‘http://hadoop000:9200/cdn/traffic/_mapping?pretty' -d ‘{
“traffic”:{
“properties”:{
“domain”:{“type”:”keyword”},
“traffics”:{“type”:”long”},
“time”:{“type”:”date”,”format”: “yyyy-MM-dd HH:mm”}
}
}
}
‘
作业:
1)代码我们都是本地IDEA中运行的,将代码打包,运行在YARN上
2)把代码中写死的信息(ip port)改成读配置的方式
需求:CDN业务
userid对应多个域名
userid: 8000000
domains:
v1.go2yd.com
v2.go2yd.com
v3.go2yd.com
v4.go2yd.com
vmi.go2yd.com
userid: 8000001
test.gifshow.com
用户id和域名的映射关系
从日志里能拿到domain,还得从另外一个表(MySQL)里面去获取userid和domain的映射关系
CREATE TABLE user_domain_config(
id int unsigned auto_increment,
user_id varchar(40) not null,
domain varchar(40) not null,
primary key (id)
);
insert into user_domain_config(user_id,domain) values(‘8000000’,’v1.go2yd.com’);
insert into user_domain_config(user_id,domain) values(‘8000000’,’v2.go2yd.com’);
insert into user_domain_config(user_id,domain) values(‘8000000’,’v3.go2yd.com’);
insert into user_domain_config(user_id,domain) values(‘8000000’,’v4.go2yd.com’);
insert into user_domain_config(user_id,domain) values(‘8000000’,’vmi.go2yd.com’);
在做实时数据清洗的时候,不仅需要处理raw日志,还需要关联MySQL表里的数据
自定义一个Flink去读MySQL数据的数据源,然后把两个Stream关联起来
Flink进行数据的清洗
读取Kafka的数据
读取MySQL的数据
connect
业务逻辑的处理分析:水印 WindowFunction
==> ES 注意数据类型 <= Kibana 图形化的统计结果展示Kibana:各个环节的监控 监控图形化
1 30
2 40
3 300
4 35
我们已经实现的 + CDN业务文档的描述 ==> 扩展
12.Flink版本升级
1)代码层面 pom.xml flink.version
2)服务器运行环境的层面
standalone 每个服务器都得升级Flink版本
yarn Flink仅仅是作为一个客户端进行作业的提交的,只需要在你的flink作业的提交机器上升级flink即可
3)Flink的部署包也要升级
获取到最新的Flink的源码,然后根据你的hadoop版本如何做好升级呢?
https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/upgrading.html