hadoop基础
1.大数据概述
大数据带来的技术变革
技术驱动:数据量大
存储:文件存储 ==> 分布式存储
计算:单机 ==> 分布式计算
网络:万兆
DB: RDBMS ==> NoSQL(HBase/Redis….)
大数据技术概念
单机:CPU Memory Disk
分布式并行计算/处理
船的选择
廉价:
中高价值:
运输过程拆开
货物搬到船上: 数据采集 数据存储
处理:小于多少的石头扔了 精细化的筛选
数据采集:Flume Sqoop
数据存储:Hadoop
数据处理、分析、挖掘:Hadoop、Spark、Flink....
可视化:2.初识Hadoop
Nutch、Hadoop:Doug Cutting
Spring:
学习一个新的框架,我的风格是直接查看该项目的官网地址
Hadoop
Hive
Apache社区的顶级项目:xxxx.apache.org
hadoop.apache.org
hive.apache.org
hbase.apache.org
spark.apache.org
flink.apache.org
storm.apache.org
reliable, scalable, distributed computing.
单机存储
单机计算
Hadoop:提供分布式的存储(一个文件被拆分成很多个块,并且以副本的方式存储在各个节点中)和计算
是一个分布式的系统基础架构:用户可以在不了解分布式底层细节的情况下进行使用。
分布式文件系统:HDFS实现将文件分布式存储在很多的服务器上
分布式计算框架:MapReduce实现在很多机器上分布式并行计算
分布式资源调度框架:YARN实现集群资源管理以及作业的调度
文件、块、副本
文件:test.log 200M
块(block):默认的blocksize是128M, 2个块 = 1个128M + 1个72M
副本:HDFS默认3副本
node1:blk1 blk2 X
node2:blk2
node3:blk1 blk2
node4:
node5:blk1去IoE
常用的Hadoop发行版
Apache
优点:纯开源
缺点:不同版本/不同框架之间整合 jar冲突… 吐血
CDH:https://www.cloudera.com/ 60-70%
优点:cm(cloudera manager) 通过页面一键安装各种框架、升级、impala
缺点:cm不开源、与社区版本有些许出入
Hortonworks:HDP 企业发布自己的数据平台可以直接基于页面框架进行改造
优点:原装Hadoop、纯开源、支持tez
缺点:企业级安全不开源
MapR3.分布式文件系统HDFS
HDFS概述
1) 分布式
2)commodity hardware
3)fault-tolerant 容错
4) high throughput
5) large data sets
HDFS是一个分布式的文件系统
文件系统:Linux、Windows、Mac....
目录结构: C /
存放的是文件或者文件夹
对外提供服务:创建、修改、删除、查看、移动等等
普通文件系统 vs 分布式文件系统
单机
分布式文件系统能够横跨N个机器HDFS前提和设计目标
Hardware Failure 硬件错误
每个机器只存储文件的部分数据,blocksize=128M
block存放在不同的机器上的,由于容错,HDFS默认采用3副本机制
Streaming Data Access 流式数据访问
The emphasis is on high throughput of data access
rather than low latency of data access.
Large Data Sets 大规模数据集
Moving Computation is Cheaper than Moving Data 移动计算比移动数据更划算
HDFS的架构 *****
1) NameNode(master) and DataNodes(slave)
2) master/slave的架构
3) NN:
the file system namespace
/home/hadoop/software
/app
regulates access to files by clients
4)DN:storage
5)HDFS exposes a file system namespace and allows user data to be stored in files.
6)a file is split into one or more blocks
blocksize: 128M
150M拆成2个block
7)blocks are stored in a set of DataNodes
为什么? 容错!!!
8)NameNode executes file system namespace operations:CRUD
9)determines the mapping of blocks to DataNodes
a.txt 150M blocksize=128M
a.txt 拆分成2个block 一个是block1:128M 另一个是block2:22M
block1存放在哪个DN?block2存放在哪个DN?
a.txt
block1:128M, 192.168.199.1
block2:22M, 192.168.199.2
get a.txt
这个过程对于用户来说是不感知的
10)通常情况下:1个Node部署一个组件课程环境介绍:
本课程录制的系统是Mac,所以我采用的linux客户端是mac自带的shell
如果你们是win:xshell、crt
服务器/linux地址:192.168.199.233
连接到linux环境
登陆:ssh hadoop@192.168.199.233
登陆成功以后:[hadoop@hadoop000 ~]$
linux机器:用户名hadoop、密码123456、hostname是hadoop000
创建课程中所需要的目录(合适的文件存放在合适的目录)
[hadoop@hadoop000 ~]$ mkdir software 存放课程所使用的软件安装包
[hadoop@hadoop000 ~]$ mkdir app 存放课程所有软件的安装目录
[hadoop@hadoop000 ~]$ mkdir data 存放课程中使用的数据
[hadoop@hadoop000 ~]$ mkdir lib 存放课程中开发过的作业jar存放的目录
[hadoop@hadoop000 ~]$ mkdir shell 存放课程中相关的脚本
[hadoop@hadoop000 ~]$ mkdir maven_resp 存放课程中使用到的maven依赖包存放的目录
学员问:root密码
切换hadoop到root用户:[hadoop@hadoop000 ~]$ sudo -i
切换root到hadoop用户:[root@hadoop000 ~]# su hadoop
我OOTB环境中创建的hadoop用户是有sudo权限:sudo vi /etc/hosts
Linux版本:
以前的课程是centos6.4,本次课程升级成centos7
Hadoop环境搭建
使用的Hadoop相关版本:CDH
CDH相关软件包下载地址:http://archive.cloudera.com/cdh5/cdh/5/
Hadoop使用版本:hadoop-2.6.0-cdh5.15.1
Hadoop下载:wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.15.1.tar.gz
Hive使用版本:hive-1.1.0-cdh5.15.1
Hadoop/Hive/Spark相关框架的学习:
使用单机版足够 *
如果使用集群学习会导致:从入门到放弃
使用Linux/Mac学习
一定不要使用Windows搭建Hadoop环境
所以Linux基础是要会的 *
Hadoop安装前置要求
Java 1.8+
ssh
安装Java
拷贝本地软件包到服务器:scp jdk-8u91-linux-x64.tar.gz hadoop@192.168.199.233:/software//app/:tar -zvxf jdk-8u91-linux-x64.tar.gz -C ~/app/
解压jdk到
把jdk配置系统环境变量中: ~/.bash_profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91
export PATH=$JAVA_HOME/bin:$PATH
使得配置修改生效:source .bash_profile
验证:java -version
安装ssh无密码登陆
ls
ls -a
ls -la 并没有发现一个.ssh的文件夹
ssh-keygen -t rsa 一路回车
cd ~/.ssh
[hadoop@hadoop000 .ssh]$ ll
总用量 12
-rw------- 1 hadoop hadoop 1679 10月 15 02:54 id_rsa 私钥
-rw-r--r-- 1 hadoop hadoop 398 10月 15 02:54 id_rsa.pub 公钥
-rw-r--r-- 1 hadoop hadoop 358 10月 15 02:54 known_hosts
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keysHadoop(HDFS)安装
下载
解压:~/app
添加HADOOP_HOME/bin到系统环境变量
修改Hadoop配置文件
hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop000:8020</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/tmp</value>
</property>
slaves
hadoop000
启动HDFS:
第一次执行的时候一定要格式化文件系统,不要重复执行: hdfs namenode -format
启动集群:$HADOOP_HOME/sbin/start-dfs.sh
验证:
[hadoop@hadoop000 sbin]$ jps
60002 DataNode
60171 SecondaryNameNode
59870 NameNode
http://192.168.199.233:50070
如果发现jps ok,但是浏览器不OK? 十有八九是防火墙问题
查看防火墙状态:sudo firewall-cmd --state
关闭防火墙: sudo systemctl stop firewalld.service
禁止防火墙开机启动:hadoop软件包常见目录说明
bin:hadoop客户端名单
etc/hadoop:hadoop相关的配置文件存放目录
sbin:启动hadoop相关进程的脚本
share:常用例子
注意:
start/stop-dfs.sh与hadoop-daemons.sh的关系
start-dfs.sh =
hadoop-daemons.sh start namenode
hadoop-daemons.sh start datanode
hadoop-daemons.sh start secondarynamenode
stop-dfs.sh =
….
HDFS命令行操作 *****
shell-like
mkdir ls ….
hadoop fs [generic options]
[-appendToFile
[-cat [-ignoreCrc]
[-chgrp [-R] GROUP PATH…]
[-chmod [-R] <MODE[,MODE]… | OCTALMODE> PATH…]
[-chown [-R] [OWNER][:[GROUP]] PATH…]
[-copyFromLocal [-f] [-p] [-l]
[-copyToLocal [-p] [-ignoreCrc] [-crc]
[-count [-q] [-h] [-v] [-x]
[-cp [-f] [-p | -p[topax]]
[-df [-h] [
[-du [-s] [-h] [-x]
[-get [-p] [-ignoreCrc] [-crc]
[-getmerge [-nl]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [
[-mkdir [-p]
[-moveFromLocal
[-moveToLocal
[-mv
[-put [-f] [-p] [-l]
[-rm [-f] [-r|-R] [-skipTrash]
[-rmdir [–ignore-fail-on-non-empty]
[-text [-ignoreCrc]
hadoop常用命令:
hadoop fs -ls /
hadoop fs -put
hadoop fs -copyFromLocal
hadoop fs -moveFromLocal
hadoop fs -cat
hadoop fs -text
hadoop fs -get
hadoop fs -mkdir
hadoop fs -mv 移动/改名
hadoop fs -getmerge
hadoop fs -rm
hadoop fs -rmdir
hadoop fs -rm -r
HDFS存储扩展:
put: 1file ==> 1…n block ==> 存放在不同的节点上的
get: 去nn上查找这个file对应的元数据信息
了解底层的存储机制这才是我们真正要学习的东西,掌握API那是毛毛雨
使用HDFS API的方式来操作HDFS文件系统
IDEA/Eclipse
Java
使用Maven来管理项目
拷贝jar包
我的所有课程都是使用maven来进行管理的
Caused by: org.apache.hadoop.ipc.RemoteException
(org.apache.hadoop.security.AccessControlException):
Permission denied: user=rocky, access=WRITE,
inode=”/“:hadoop:supergroup:drwxr-xr-x
HDFS操作:shell + Java API
综合性的HDFS实战:使用HDFS Java API才完成HDFS文件系统上的文件的词频统计
词频统计:wordcount
/path/1.txt
hello world hello
/path/2.txt
hello world hello
==> (hello,4) (world,2)
将统计完的结果输出到HDFS上去。
假设:有的小伙伴了解过mr、spark等等,觉得这个操作很简单
本实战的要求:只允许使用HDFS API进行操作
目的:
1)掌握HDFS API的操作
2)通过这个案例,让你们对于后续要学习的mr有一个比较好的认识
硬编码 : 非常忌讳的
==> 可配置
可插拔的开发/管理方式 plugin
副本摆放策略
1-本rack的一个节点上
2-另外一个rack的节点上
3-与2相同的rack的另外一个节点上
1-本rack的一个节点上
2-本rack的另外一个节点上
3-不同rack的一个节点上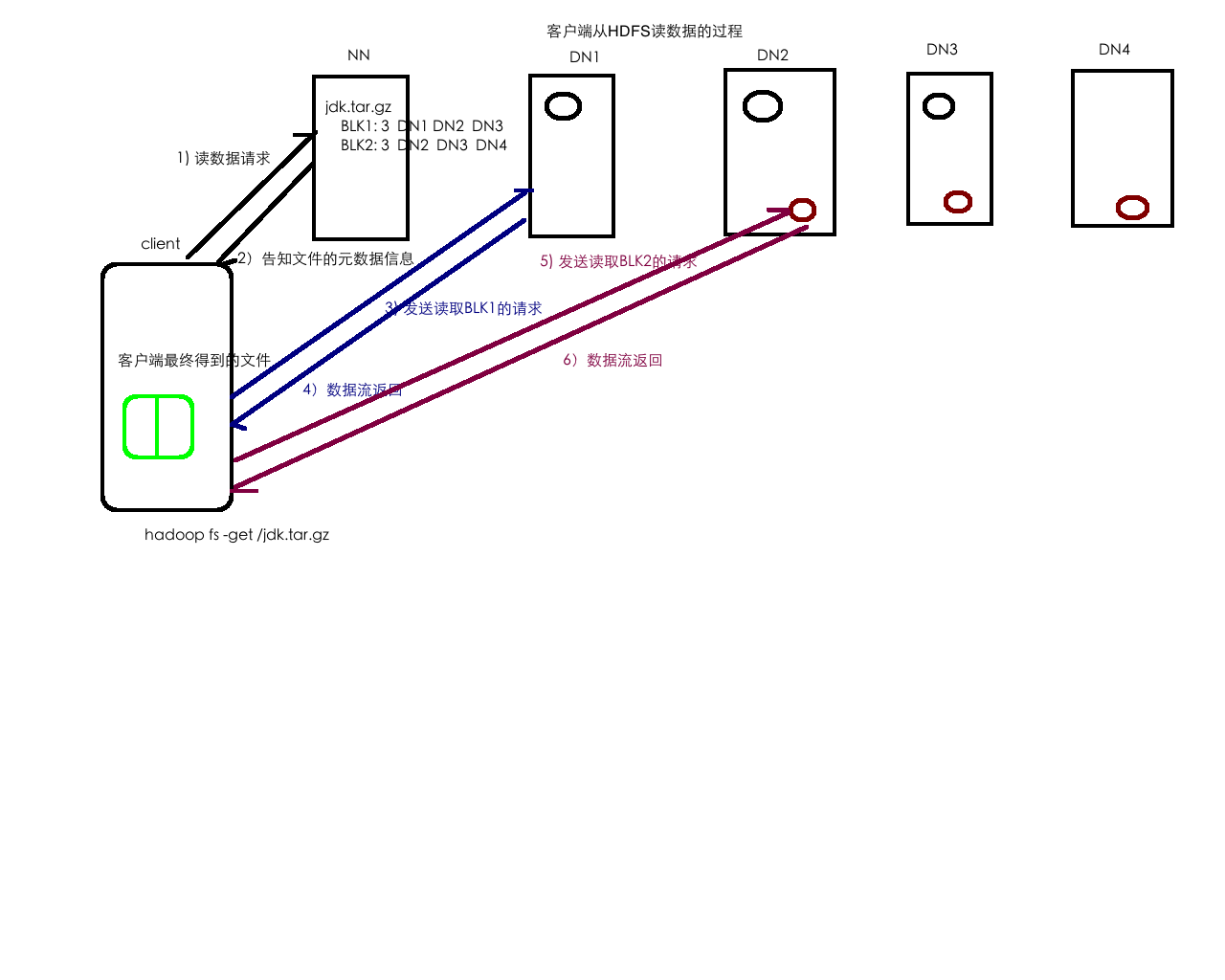
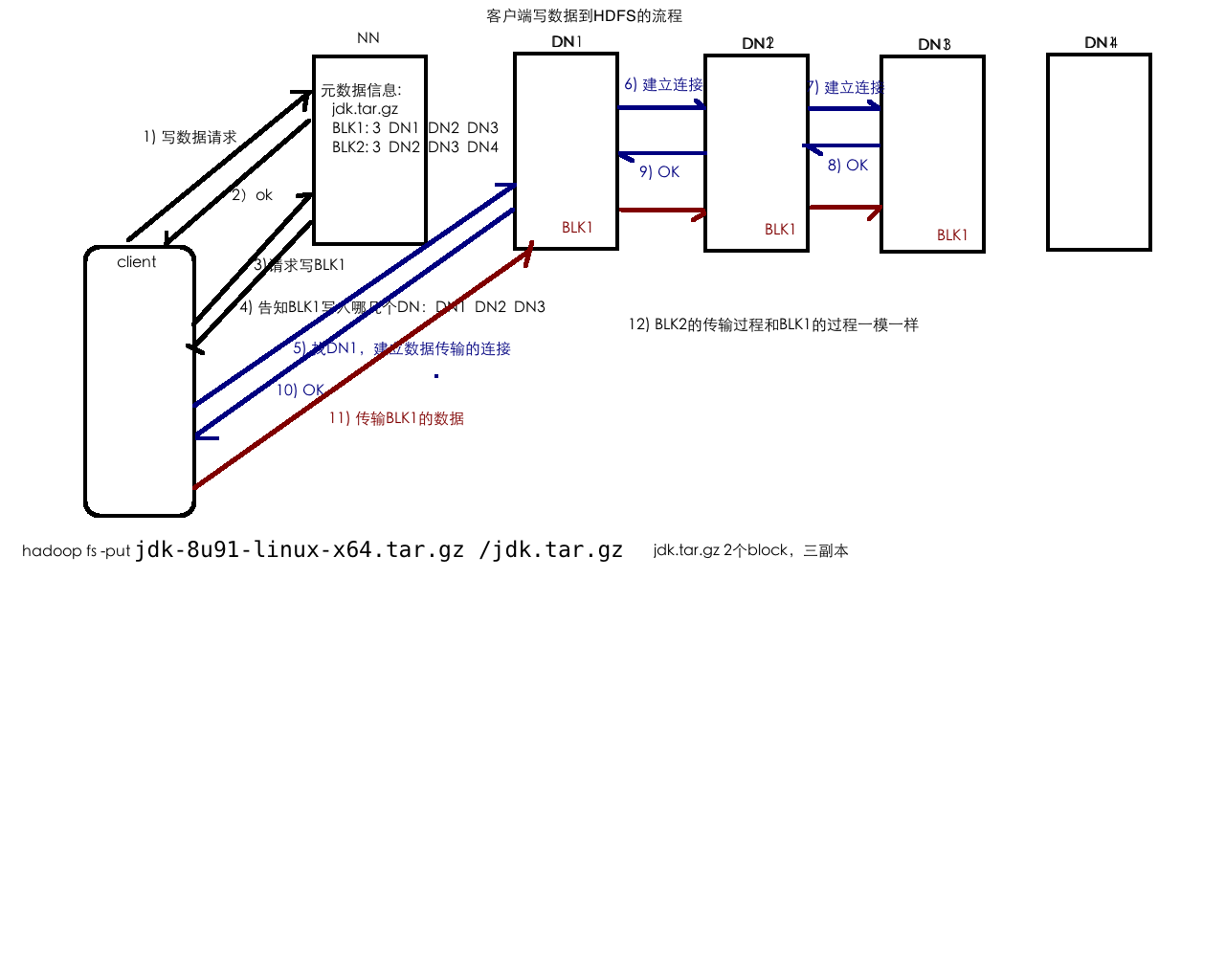
HDFS的元数据管理
元数据:HDFS的目录结构以及每个文件的BLOCK信息(id,副本系数、block存放在哪个DN上)
存在什么地方:对应配置 ${hadoop.tmp.dir}/name/……
元数据存放在文件中:
/test1
/test1/a.txt
/test2
/test2/1.txt
/test2/2.txt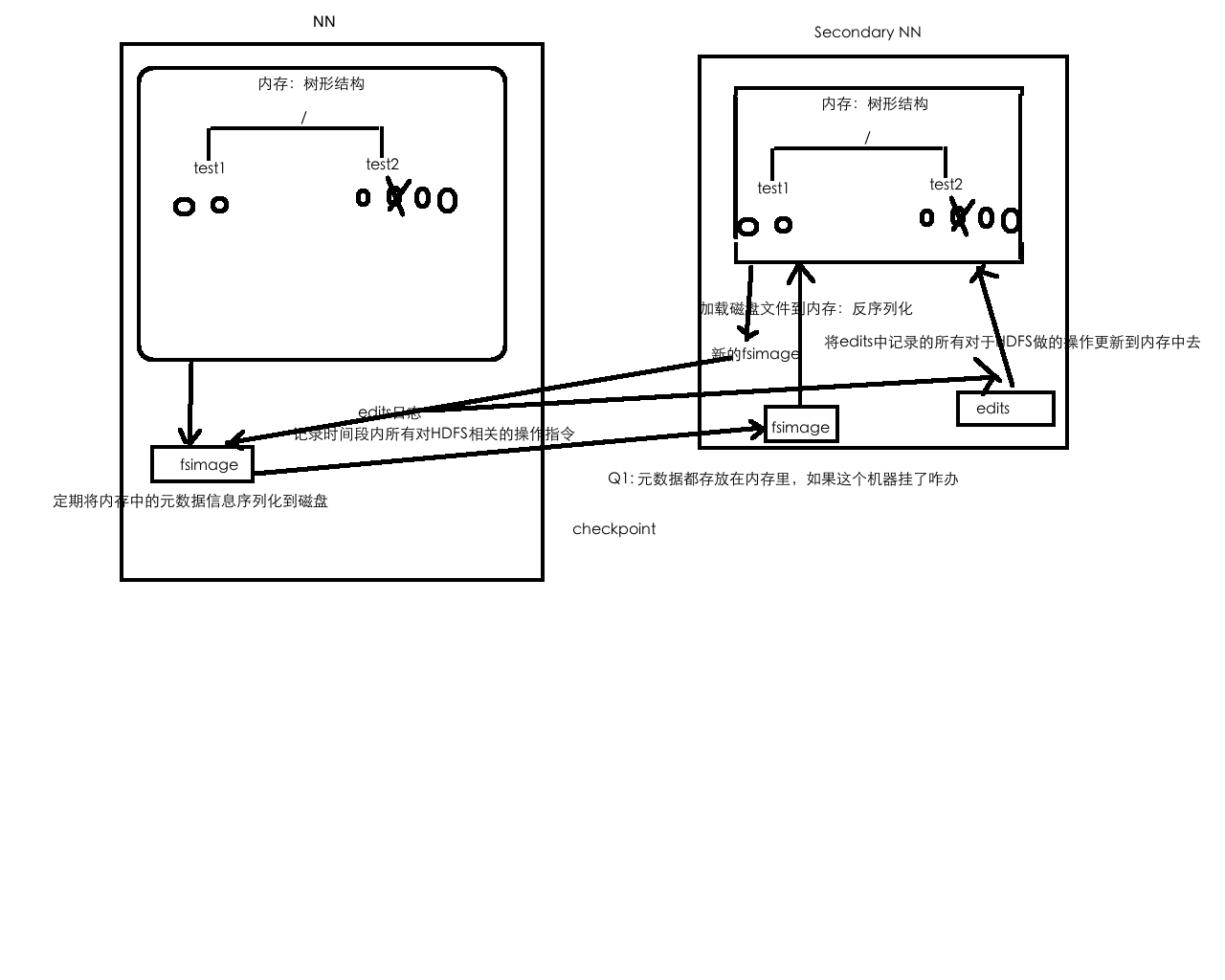
4.分布式计算框架MapReduce
词频统计、流量统计
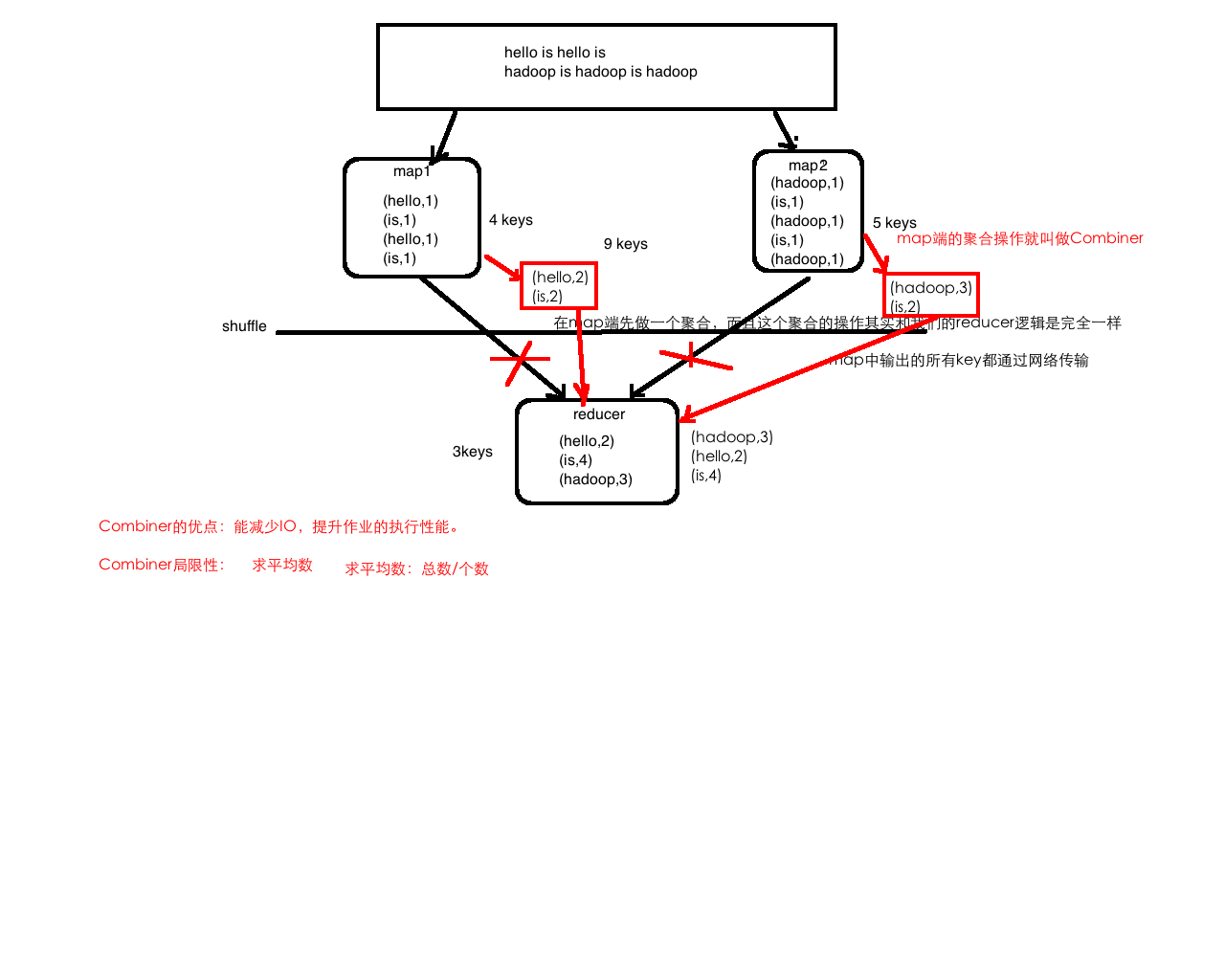
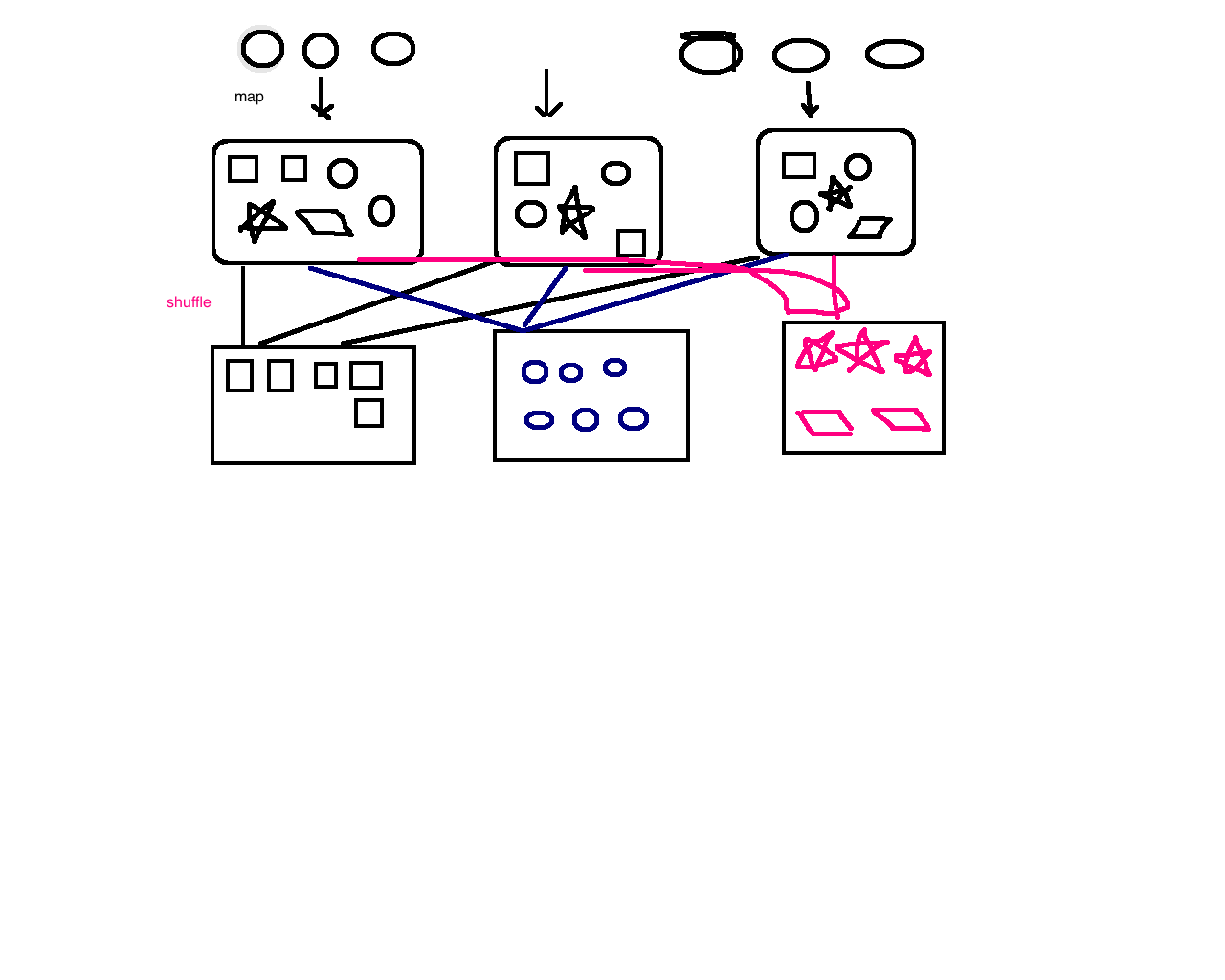
5.资源调度框架YARN
YARN产生背景
MapReduce1.x ==> MapReduce2.x
master/slave : JobTracker/TaskTracker
JobTracker:单点、压力大
仅仅只能够支持mapreduce作业
资源利用率
所有的计算框架运行在一个集群中,共享一个集群的资源,按需分配!master: resource management:ResourceManager (RM)
job scheduling/monitoring:per-application ApplicationMaster (AM)
slave: NodeManager (NM)
YARN架构
Client、ResourceManager、NodeManager、ApplicationMaster
master/slave: RM/NM
Client: 向RM提交任务、杀死任务等
ApplicationMaster:
每个应用程序对应一个AM
AM向RM申请资源用于在NM上启动对应的Task
数据切分
为每个task向RM申请资源(container)
NodeManager通信
任务的监控
NodeManager: 多个
干活
向RM发送心跳信息、任务的执行情况
接收来自RM的请求来启动任务
处理来自AM的命令
ResourceManager:集群中同一时刻对外提供服务的只有1个,负责资源相关
处理来自客户端的请求:提交、杀死
启动/监控AM
监控NM
资源相关
container:任务的运行抽象
memory、cpu….
task是运行在container里面的
可以运行am、也可以运行map/reduce task
提交自己开发的MR作业到YARN上运行的步骤:
1)mvn clean package -DskipTests
windows/Mac/Linux ==> Maven
2)把编译出来的jar包(项目根目录/target/…jar)以及测试数据上传到服务器
scp xxxx hadoop@hostname:directory
3) 把数据上传到HDFS
hadoop fs -put xxx hdfspath
4) 执行作业
hadoop jar xxx.jar 完整的类名(包名+类名) args…..
5) 到YARN UI(8088) 上去观察作业的运行情况
6)到输出目录去查看对应的输出结果
6.电商项目实战Hadoop实现
用户行为日志:
每一次访问的行为(访问、搜索)产生的日志
历史行为数据 <== 历史订单
==> 推荐
==> 订单的转换量/率
原始日志字段说明:
第二个字段:url
第十四字段:ip
第十八字段:time
==> 字段的解析
ip => 地市:国家、省份、城市
url => 页面ID
referer7.数据仓库Hive
HDFS上的文件并没有schema的概念
schema?
Hive底层执行引擎支持:MR/Tez/Spark
统一元数据管理:
Hive数据是存放在HDFS
元数据信息(记录数据的数据)是存放在MySQL中
SQL on Hadoop: Hive、Spark SQL、impala….
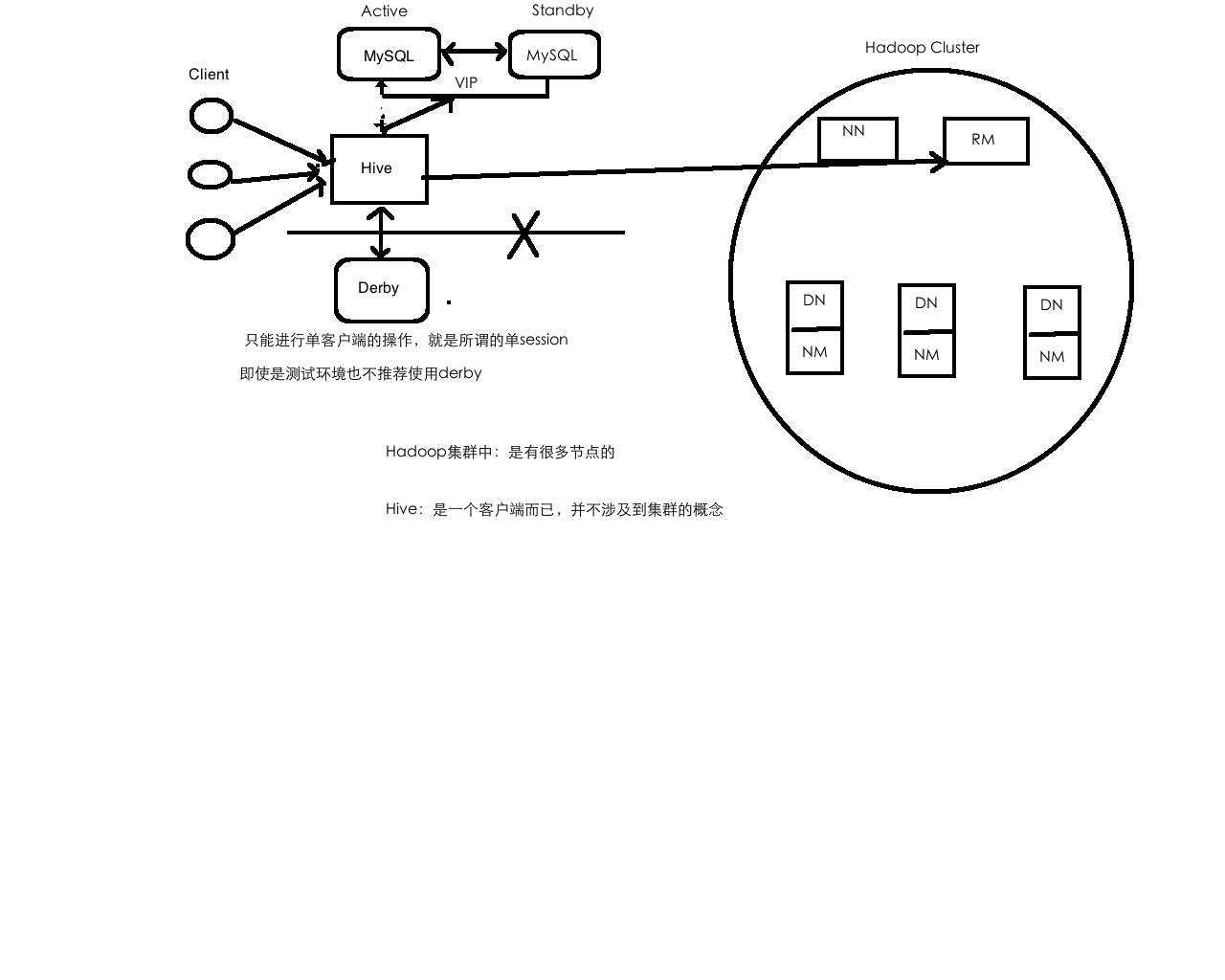
Hive体系架构
client:shell、thrift/jdbc(server/jdbc)、WebUI(HUE/Zeppelin)
metastore:==> MySQL
database:name、location、owner….
table:name、location、owner、column name/type ….
Hive部署
1)下载
2)解压到~/app
3)添加HIVE_HOME到系统环境变量
4)修改配置
hive-env.sh
hive-site.xml
5) 拷贝MySQL驱动包到$HIVE_HOME/lib
6) 前提是要准备安装一个MySQL数据库,yum install去安装一个MySQL数据库
https://www.cnblogs.com/julyme/p/5969626.html
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop000:3306/hadoop_hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>Hive部署架构图
DDL:Hive Data Definition Language
create、delete、alter…
Hive数据抽象/结构
database HDFS一个目录
table HDFS一个目录
data 文件
partition 分区表 HDFS一个目录
data 文件
bucket 分桶 HDFS一个文件
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];CREATE DATABASE IF NOT EXISTS hive;
CREATE DATABASE IF NOT EXISTS hive2 LOCATION ‘/test/location’;
CREATE DATABASE IF NOT EXISTS hive3
WITH DBPROPERTIES(‘creator’=’pk’);
/user/hive/warehouse是Hive默认的存储在HDFS上的路径
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
LOAD DATA LOCAL INPATH ‘/home/hadoop/data/emp.txt’ OVERWRITE INTO TABLE emp;
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]LOCAL:本地系统,如果没有local那么就是指的HDFS的路径
OVERWRITE:是否数据覆盖,如果没有那么就是数据追加
LOAD DATA LOCAL INPATH ‘/home/hadoop/data/emp.txt’ OVERWRITE INTO TABLE emp;
LOAD DATA INPATH ‘hdfs://hadoop000:8020/data/emp.txt’ INTO TABLE emp;
INSERT OVERWRITE LOCAL DIRECTORY ‘/tmp/hive/‘
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’
select empno,ename,sal,deptno from emp;
聚合: max/min/sum/avg
分组函数: group by
求每个部门的平均工资
出现在select中的字段,如果没有出现在聚合函数里,那么一定要实现在group by里
select deptno, avg(sal) from emp group by deptno;
求每个部门、工作岗位的平均工资
select deptno,job avg(sal) from emp group by deptno,job;
求每个部门的平均工资大于2000的部门
select deptno, avg(sal) avg_sal from emp group by deptno where avg_sal>2000;
对于分组函数过滤要使用having
select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal>2000; join : 多表
emp
dept
CREATE TABLE dept(
deptno int,
dname string,
loc string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
LOAD DATA LOCAL INPATH ‘/home/hadoop/data/dept.txt’ OVERWRITE INTO TABLE dept;
explain EXTENDED
select
e.empno,e.ename,e.sal,e.deptno,d.dname
from emp e join dept d
on e.deptno=d.deptno;
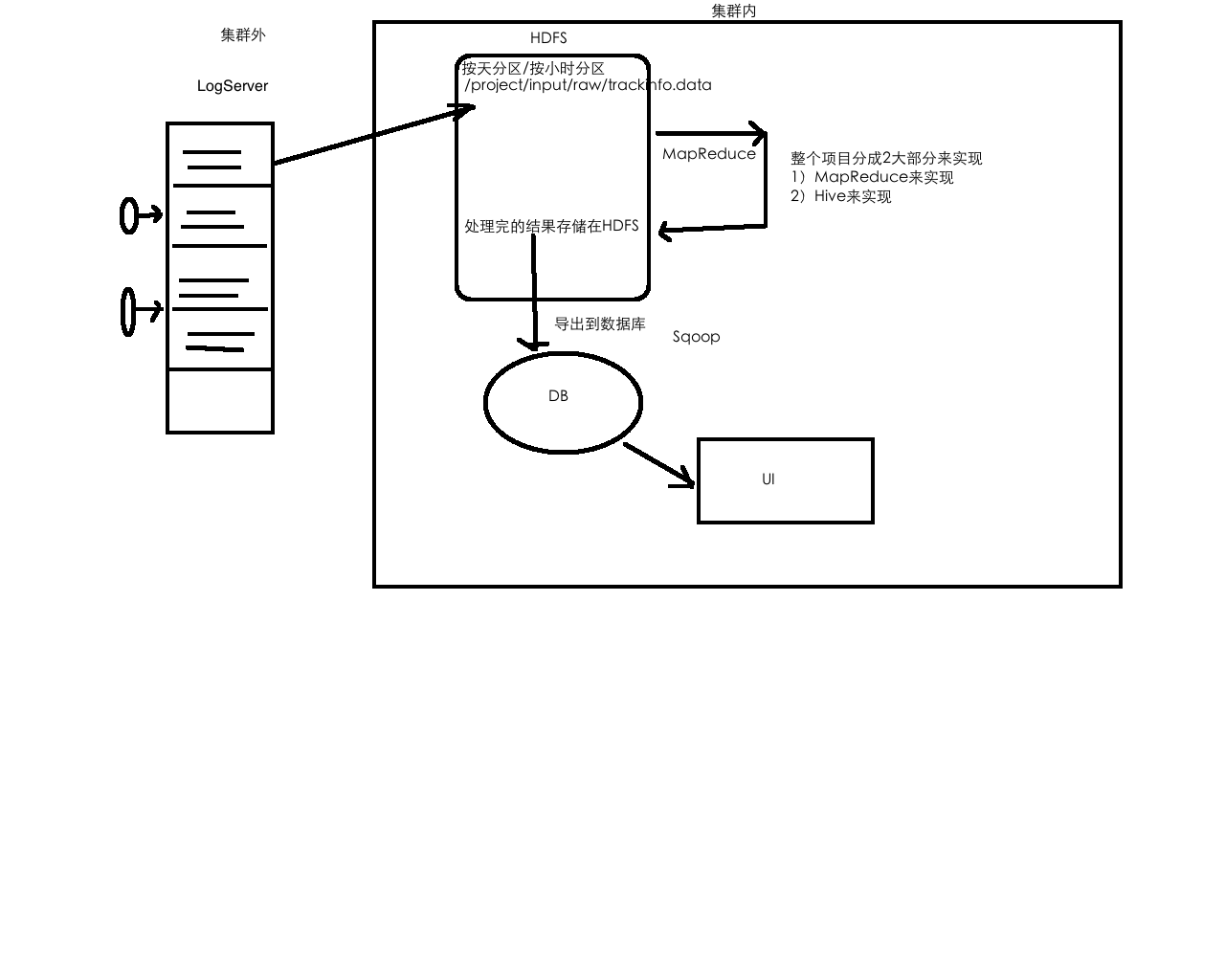
8.电商项目实战Hive实现
技术架构图
Hive外部表
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
LOAD DATA LOCAL INPATH ‘/home/hadoop/data/emp.txt’ OVERWRITE INTO TABLE emp;
MANAGED_TABLE:内部表
删除表:HDFS上的数据被删除 & Meta也被删除
CREATE EXTERNAL TABLE emp_external(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’
location ‘/external/emp/‘;
LOAD DATA LOCAL INPATH ‘/home/hadoop/data/emp.txt’ OVERWRITE INTO TABLE emp_external;
EXTERNAL_TABLE
HDFS上的数据不被删除 & Meta被删除
分区表
create external table track_info(
ip string,
country string,
province string,
city string,
url string,
time string,
page string
) partitioned by (day string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’
location ‘/project/trackinfo/‘;
crontab表达式进行调度
Azkaban调度:ETLApp==>其他的统计分析
PySpark及调度系统
https://coding.imooc.com/class/chapter/249.html#Anchor
LOAD DATA INPATH ‘hdfs://hadoop000:8020/project/input/etl’ OVERWRITE INTO TABLE track_info partition(day=’2013-07-21’);
select count(*) from track_info where day=’2013-07-21’ ;
select province,count(*) as cnt from track_info where day=’2013-07-21’ group by province ;
省份统计表
create table track_info_province_stat(
province string,
cnt bigint
) partitioned by (day string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
insert overwrite table track_info_province_stat partition(day=’2013-07-21’)
select province,count(*) as cnt from track_info where day=’2013-07-21’ group by province ;
到现在为止,我们统计的数据已经在Hive表track_info_province_stat
而且这个表是一个分区表,后续统计报表的数据可以直接从这个表中查询
也可以将hive表的数据导出到RDBMS(sqoop)
1)ETL
2)把ETL输出的数据加载到track_info分区表里
3)各个维度统计结果的数据输出到各自维度的表里(track_info_province_stat)
4)将数据导出(optional)
如果一个框架不能落地到SQL层面,这个框架就不是一个非常适合的框架
9.Hadoop分布式集群搭建
Hadoop集群规划
HDFS: NN DN
YARN: RM NM
hadoop000 192.168.199.234
NN RM
DN NM
hadoop001 192.168.199.235
DN NM
hadoop002 192.168.199.236
DN NM
(每台)
/etc/hostname: 修改hostname(hadoop000/hadoop001/hadoop002)
/etc/hosts: ip和hostname的映射关系
192.168.199.234 hadoop000
192.168.199.235 hadoop001
192.168.199.236 hadoop002
192.168.199.234 localhost
前置安装 ssh
(每台)ssh免密码登陆:ssh-keygen -t rsa
在hadoop000机器上进行caozuo
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop000
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop001
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002
JDK安装
1)先在hadoop000机器上部署了jdk
2)将jdk bin配置到系统环境变量
3)将jdk拷贝到其他节点上去(从hadoop000机器出发)
scp -r jdk1.8.0_91 hadoop@hadoop001:/app//app/
scp -r jdk1.8.0_91 hadoop@hadoop002:
scp /.bash_profile hadoop@hadoop001:/
scp /.bash_profile hadoop@hadoop002:/
Hadoop部署
1)hadoop-env.sh
JAVA_HOME
2) core-site.xml
3) hdfs-site.xml
4) yarn-site.xml
6) slaves
7) 分发hadoop到其他机器
scp -r hadoop-2.6.0-cdh5.15.1 hadoop@hadoop001:/app//app/
scp -r hadoop-2.6.0-cdh5.15.1 hadoop@hadoop002:
scp /.bash_profile hadoop@hadoop001:/
scp /.bash_profile hadoop@hadoop002:/
8) NN格式化: hadoop namenode -format
9) 启动HDFS
10) 启动YARN