面经总结
hive的metastore选择
hive的metastore存储方式:
一、使用derby数据库存储元数据。
使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,否则会提示如下错误(这是一个很常见的错误)。
二、使用本机mysql服务器存储元数据。这种存储方式需要在本地运行一个mysql服务器,并作如下配置(下面两种使用mysql的方式,需要将mysql的jar包拷贝到$HIVE_HOME/lib目录下)。
三、使用远端mysql服务器存储元数据。这种存储方式需要在远端服务器运行一个mysql服务器,并且需要在Hive服务器启动meta服务。
kafka中consumer和partition的对应关系
一个partition只能被同组的一个consumer消费,同组的consumer则起到均衡效果。
- 消费者多于partition
多余的消费者空闲
- 消费者少于和等于partition
即消息在同一个组之间的消费者之间均分
- 多个消费者组
即组与组之间的消息是否被消费是相互隔离互不影响的。
synchronized实现原理
详细理解
链接:https://blog.csdn.net/javazejian/article/details/72828483
简单理解
链接:https://blog.csdn.net/jinjiniao1/article/details/91546512
synchronized的实现原理和应用总结
(1)synchronized同步代码块:synchronized关键字经过编译之后,会在同步代码块前后分别形成monitor enter和monitor exit字节码指令,在执行monitorenter指令的时候,首先尝试获取对象的锁,如果这个锁没有被锁定或者当前线程已经拥有了那个对象的锁,锁的计数器就加1,在执行monitorexit指令时会将锁的计数器减1,当减为0的时候就释放锁。如果获取对象锁一直失败,那当前线程就要阻塞等待,直到对象锁被另一个线程释放为止。
(2)同步方法:方法级的同步是隐式的,无须通过字节码指令来控制,JVM可以从方法常量池的方法表结构中的ACC_SYNCHRONIZED访问标志得知一个方法是否声明为同步方法。当方法调用的时,调用指令会检查方法的ACC_SYNCHRONIZED访问标志是否被设置,如果设置了,执行线程就要求先持有monitor对象,然后才能执行方法,最后当方法执行完(无论是正常完成还是非正常完成)时释放monitor对象。在方法执行期间,执行线程持有了管程,其他线程都无法再次获取同一个管程。
JVM规范中对monitorenter和monitorexit指令的描述如下:
monitorenter:
每个对象都有一个监视器锁(monitor)与之对应。当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
1、如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
2、如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
3.如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
monitorexit:
执行monitorexit的线程必须是objectref所对应的monitor的所有者。
指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个monitor的所有权。
同时我们还必须注意到的是在Java早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的Mutex Lock来实现的,而操作系统实现线程之间的切换时需要从用户态转换到核心态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的synchronized效率低的原因。庆幸的是在Java 6之后Java官方对从JVM层面对synchronized较大优化,所以现在的synchronized锁效率也优化得很不错了,Java 6之后,为了减少获得锁和释放锁所带来的性能消耗,引入了轻量级锁和偏向锁,接下来我们将简单了解一下Java官方在JVM层面对synchronized锁的优化。
Java虚拟机对synchronized的优化
锁的状态总共有四种,无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁,但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级,关于重量级锁,前面我们已详细分析过,下面我们将介绍偏向锁和轻量级锁以及JVM的其他优化手段,这里并不打算深入到每个锁的实现和转换过程更多地是阐述Java虚拟机所提供的每个锁的核心优化思想,毕竟涉及到具体过程比较繁琐,如需了解详细过程可以查阅《深入理解Java虚拟机原理》。
偏向锁
偏向锁的核心思想是,如果一个线程获得了锁,那么锁就进入偏向模式,此时Mark Word 的结构也变为偏向锁结构,当这个线程再次请求锁时,无需再做任何同步操作,即获取锁的过程,这样就省去了大量有关锁申请的操作,从而也就提供程序的性能。
轻量级锁
轻量级锁能够提升程序性能的依据是“对绝大部分的锁,在整个同步周期内都不存在竞争”,注意这是经验数据。需要了解的是,轻量级锁所适应的场景是线程交替执行同步块的场合,如果存在同一时间访问同一锁的场合,就会导致轻量级锁膨胀为重量级锁。
自旋锁
这是基于在大多数情况下,线程持有锁的时间都不会太长,如果直接挂起操作系统层面的线程可能会得不偿失,毕竟操作系统实现线程之间的切换时需要从用户态转换到核心态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
重量级锁
获取不到锁的线程进入阻塞,获取到锁的线程,在释放锁时会有唤醒操作。
重量级锁是依赖对象内部的monitor锁来实现的,而monitor又依赖操作系统的MutexLock(互斥锁)来实现的,所以重量级锁也被成为互斥锁。
当系统检查到锁是重量级锁之后,会把等待想要获得锁的线程进行阻塞,被阻塞的线程不会消耗cup。但是阻塞或者唤醒一个线程时,都需要操作系统来帮忙,这就需要从用户态转换到内核态,而转换状态是需要消耗很多时间的,有可能比用户执行代码的时间还要长。
锁消除
Java虚拟机在JIT编译时(可以简单理解为当某段代码即将第一次被执行时进行编译,又称即时编译),通过对运行上下文的扫描,去除不可能存在共享资源竞争的锁,通过这种方式消除没有必要的锁,可以节省毫无意义的请求锁时间,
数据仓库分层
一、数据运营层:ODS(Operational Data Store)
“面向主题的”数据运营层,也叫ODS层,是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的 ETL 之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。
建议做过多的数据清洗工作,原封不动地接入原始数据即可,至于数据的去噪、去重、异常值处理等过程可以放在后面的DWD层来做。
二、数据仓库层:DW(Data Warehouse)
数据仓库层是我们在做数据仓库时要核心设计的一层,在这里,从 ODS 层中获得的数据按照主题建立各种数据模型。DW层又细分为 DWD(Data Warehouse Detail)层、DWM(Data WareHouse Middle)层和DWS(Data WareHouse Servce)层。
\1. 数据明细层:DWD(Data Warehouse Detail)
维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。
部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性。
\2. 数据中间层:DWM(Data WareHouse Middle)
轻度聚合操作,生成一系列的中间表,提升公共指标的复用性。
直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。
\3. 数据服务层:DWS(Data WareHouse Servce)
又称数据集市或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
一般来讲,该层的数据表会相对比较少,一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
在实际计算中,如果直接从DWD或者ODS计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在DWM层先计算出多个小的中间表,然后再拼接成一张DWS的宽表。由于宽和窄的界限不易界定,也可以去掉DWM这一层,只留DWS层,将所有的数据在放在DWS亦可。
三、数据应用层:APP(Application)
应用层的需求来创建表。
hadoop安装过程中遇到的问题
首先我使用的hadoop的cdn版本,比所有的组件都使用社区版,可能会出现版本问题。
其次是自己学习过程中,基本上以单结点,或者三节点集群为主,问题较少
- 关闭防火墙
- 配置文件要细心
namenode format 失败
切换到root用户,否则容易没有权限。
hive工作原理
1.词法分析/语法分析:使用antlr将SQL语句解析成抽象语法树-AST
2.语义分析:从Megastore获取模式信息,验证SQL语句中队表名,列名,以及数据类型的检查和隐式转换,以及Hive提供的函数和用户自定义的函数(UDF/UAF)
3.逻辑计划生产:生成逻辑计划-算子树
4.逻辑计划优化:对算子树进行优化,包括列剪枝,分区剪枝,谓词下推等
5.物理计划生成:将逻辑计划生产包含由MapReduce任务组成的DAG的物理计划
6.物理计划执行:将DAG发送到Hadoop集群进行执行
7.将查询结果返回
除了Synchronized,还有什么可以保证多线程的安全
ReentrantLock
ReentrantLock主要利用CAS+AQS队列来实现。它支持公平锁和非公平锁,两者的实现类似。
CAS:Compare and Swap,比较并交换。CAS有3个操作数:内存值V、预期值A、要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。该操作是一个原子操作,被广泛的应用在Java的底层实现中。在Java中,CAS主要是由sun.misc.Unsafe这个类通过JNI调用CPU底层指令实现
AbstractQueuedSynchronizer简称AQS
是一个用于构建锁和同步容器的框架。事实上concurrent包内许多类都是基于AQS构建,例如ReentrantLock,Semaphore,CountDownLatch,ReentrantReadWriteLock,FutureTask等。AQS解决了在实现同步容器时设计的大量细节问题。
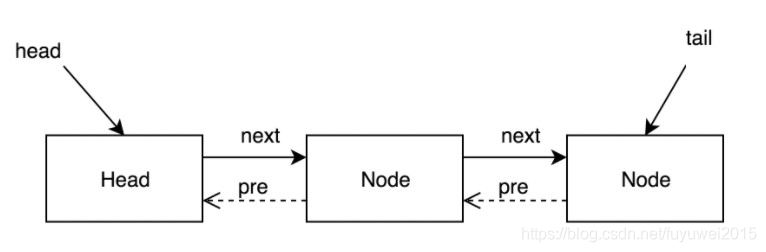
AQS使用一个FIFO的队列表示排队等待锁的线程,队列头节点称作“哨兵节点”或者“哑节点”,它不与任何线程关联。其他的节点与等待线程关联,每个节点维护一个等待状态waitStatus
ReentrantLock的基本实现可以概括为:先通过CAS尝试获取锁。如果此时已经有线程占据了锁,那就加入AQS队列并且被挂起。当锁被释放之后,排在CLH队列队首的线程会被唤醒,然后CAS再次尝试获取锁。在这个时候,如果:
非公平锁:如果同时还有另一个线程进来尝试获取,那么有可能会让这个线程抢先获取;
公平锁:如果同时还有另一个线程进来尝试获取,当它发现自己不是在队首的话,就会排到队尾,由队首的线程获取到锁。
union和union all的区别
一、区别1:取结果的交集
1、union: 对两个结果集进行并集操作, 不包括重复行,相当于distinct, 同时进行默认规则的排序;
2、union all: 对两个结果集进行并集操作, 包括重复行, 即所有的结果全部显示, 不管是不是重复;
二、区别2:获取结果后的操作
1、union: 会对获取的结果进行排序操作
2、union all: 不会对获取的结果进行排序操作
你是如何模拟数据?
写数据上报的接口,接口中,使用kafkaproducer想相应的topic发送数据。
模拟的json数据,通过发送http的post请求。调用数据上报的接口。