计算机网络
TCP的拥塞控制
- 拥塞
拥塞:即对资源的需求超过了可用的资源。若网络中许多资源同时供应不足,网络的性能就要明显变坏,整个网络的吞吐量随之负荷的增大而下降。
拥塞控制:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提:网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机、路由器,以及与降低网络传输性能有关的所有因素。
流量控制:指点对点通信量的控制,是端到端正的问题。流量控制所要做的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
几种拥塞控制方法
慢开始( slow-start )、拥塞避免( congestion avoidance )、快重传( fast retransmit )和快恢复( fast recovery )。
2.1 慢开始和拥塞避免
发送方维持一个拥塞窗口 cwnd ( congestion window )的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。发送方让自己的发送窗口等于拥塞。
发送方控制拥塞窗口的原则是:只要网络没有出现拥塞,拥塞窗口就再增大一些,以便把更多的分组发送出去。但只要网络出现拥塞,拥塞窗口就减小一些,以减少注入到网络中的分组数。
慢开始算法:当主机开始发送数据时,如果立即所大量数据字节注入到网络,那么就有可能引起网络拥塞,因为现在并不清楚网络的负荷情况。因此,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是说,由小到大逐渐增大拥塞窗口数值。通常在刚刚开始发送报文段时,先把拥塞窗口 cwnd 设置为一个最大报文段MSS的数值。而在每收到一个对新的报文段的确认后,把拥塞窗口增加至多一个MSS的数值。用这样的方法逐步增大发送方的拥塞窗口 cwnd ,可以使分组注入到网络的速率更加合理。
数据库结构
如何设计一个关系型数据库?
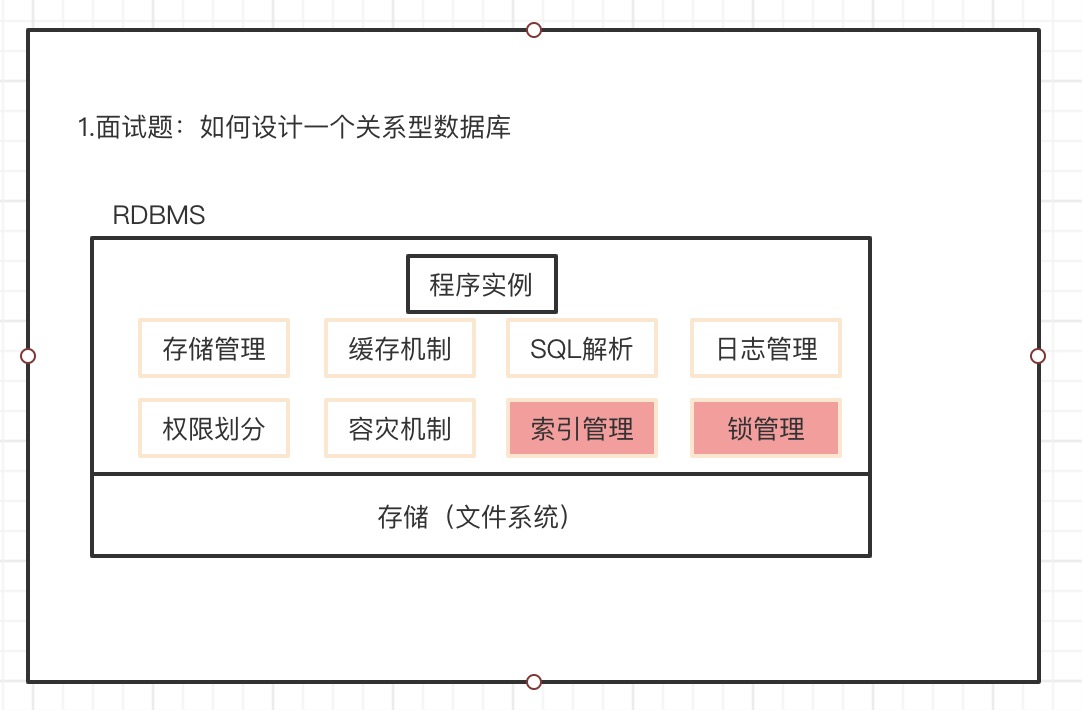
程序实例模块
- 存储模块:逻辑关系转化成物理关系的存储管理
- 缓存机制:优化执行效率
- SQL解析:进行SQL语句的解析
- 日志管理:记录操作日志
- 权限划分:进行多用户管理的权限划分
- 容灾机制:灾难恢复模块
- 索引管理:优化数据查询效率
- 锁管理:使得数据库支持并发操作
存储模块(文件系统)
- 磁盘或者固态硬盘存储所有数据
链接:https://www.pianshen.com/article/65811074520/
索引的数据结构
- 生成索引,建立二叉查找树进行二分查找
- 时间复杂度o(logn),可能变成o(n)
- 还要考虑io
- 生成索引,建立b-tree结构进行查找
- 平衡多路查找树
- 生成索引,建立b+tree结构进行查找
- b树的变体
- 生成索引,建立hash结构进行查找
myisam和innodb关于锁方面的区别是什么
- myisam支持表级锁,不支持行级锁
- innodb都支持
1 | // 共享锁 |
Ps:
innodb没有用到索引的时候,用的是表级锁
用到索引的时候,用的是行锁
数据库锁的分类
- 锁粒度划分:表级锁、行级锁、页级锁
- 锁级别划分:共享锁、排它锁
- 按加锁方式划分:自动锁、显式锁
- 按操作划分:DML锁(对数据上的操作,数据的增删改查)、DDL锁(表结构,alter table)
- 按使用方式划分:乐观锁(认为数据一般情况下,不会冲突,如果冲突则处理。实现方式:版本号、时间戳)、悲观锁(往往依赖数据库的锁机制,先取锁,再操作)
事务隔离级别以及各级别下的并发访问问题
事务并发访问引起的问题以及如何避免
- 更新丢失–mysql所有事务隔离级别在数据库层面上均可避免
- 脏读–read-committed事务隔离级别以上可避免
- 不可重复读–repeatable-read事务隔离级别以上可避免
- 幻读–serializable事务隔离级别可避免
innodb可重复读隔离级别下如何避免幻读
- 表象:快照读(非阻塞读)–伪MVCC
- 内在:next-key锁(行锁+gap锁)
当前读:select…lock in share mode,select…for update
当前读:update, delete,insert
rc,rr级别下的innodb的非阻塞读如何实现
- 数据行里的DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID字段
- undo日志
- read view
对主键索引或者唯一索引会用gap锁吗
- 如果where条件全部命中,则不会用gap锁,只会加记录锁
- 如果where条件部分命中或者全不命中,则用gap锁
gap锁会用在非唯一索引或者不走索引的当前读中
- 非唯一索引
- 不走索引
关键语法
having
- 通常和group by 一起使用
- Where过滤行,having过滤组
- sql顺序:where> group by > having
Redis
- String
String类是是二进制安全的。意思是redis的String可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个redis中value最多可以是512M。
- List
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部或者尾部。它的底层是一个链表。
总结:
它是一个字符串链表,left,right都可以插入添加
如果键不存在,创建新的链表,如果键已经存在则新增内容
如果内容全部移除。对应的键也消失。
链表的操作无论是在头和尾效率都极高,但假如是对中间元素进行操作,效率就很惨淡。
- Set
Redis的Set的histring类型的无序集合。他是通过HashTable实现的。
- Redis哈希(Hash)
Redis hash是一个键值对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
类似Java里面Map<String, Object>。
- Redis有序集合Zset(sorted set)
Redis zset和set一样也是string类型元素的集合,而且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。
redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。
在Redis里,如何从海量key中查询出某一个固定前缀所有的key?
每次只返回一小部分的键,这样不会阻塞服务器,一下子在网络传输大量数据
1 |
|
Redis持久化方式
方式
Redis支持RDB和AOF两种持久化机制,持久化功能有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数 据恢复。理解掌握持久化机制对于Redis运维非常重要
- RDB持久化
RDB持久化是把当前进程数据生成快照保存到硬盘的过程,触发RDB持久化过程分为手动触发和自动触发
1)触发机制
手动触发分别对应save和bgsave命令
·save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存 比较大的实例会造成长时间阻塞,线上环境不建议使用
·bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子 进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短
2)自动触发RDB的持久
1)使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改 时,自动触发bgsave。
2)如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点,更多细节见6.3节介绍的复制原理。
3)执行debug reload命令重新加载Redis时,也会自动触发save操作。
4)默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则 自动执行bgsave。
RDB的优缺点
RDB的优点:
RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据 快照。非常适用于备份,全量复制等场景。比如每6小时执行bgsave备份, 并把RDB文件拷贝到远程机器或者文件系统中(如hdfs),用于灾难恢复。
Redis加载RDB恢复数据远远快于AOF的方式。
RDB的缺点:
RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运 行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式 的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题。
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决。
AOF持久化
AOF(append only file)持久化:以独立日志的方式记录每次写命令, 重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用 是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式
1)使用AOF
开启AOF功能需要设置配置:appendonly yes,默认不开启。AOF文件名 通过appendfilename配置设置,默认文件名是appendonly.aof。保存路径同 RDB持久化方式一致,通过dir配置指定。AOF的工作流程操作:命令写入 (append)、文件同步(sync)、文件重写(rewrite)、重启加载 (load)。
AOF过程:
1)所有的写入命令会追加到aof_buf(缓冲区)中。
2)AOF缓冲区根据对应的策略向硬盘做同步操作。
AOF为什么把命令追加到aof_buf中?Redis使用单线程响应命令,如 果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负 载。先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡
3)随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
重写后的AOF文件为什么可以变小?有如下原因:
1)进程内已经超时的数据不再写入文件。
2)旧的AOF文件含有无效命令,如del key1、hdel key2、srem keys、set a111、set a222等。重写使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令。
3)多条写命令可以合并为一个,如:lpush list a、lpush list b、lpush list c可以转化为:lpush list a b c。
AOF重写降低了文件占用空间,除此之外,另一个目的是:更小的AOF 文件可以更快地被Redis加载。
AOF重写过程可以手动触发和自动触发:
·手动触发:直接调用bgrewriteaof命令。
·自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机
加载AOF文件进行数据恢复
流程说明:
1)AOF持久化开启且存在AOF文件时,优先加载AOF文件,打印如下日志:
* DB loaded from append only file: 5.841 seconds
2)AOF关闭或者AOF文件不存在时,加载RDB文件,打印如下日志:
* DB loaded from disk: 5.586 seconds
3)加载AOF/RDB文件成功后,Redis启动成功。
4)AOF/RDB文件存在错误时,Redis启动失败并打印错误信息。
Redis管道技术(pipeline)
作用:执行命令简单的,更加快速的发送给服务器;
一个client可以通过一个socket连接发起多个请求命令。每个请求命令发出后client通常会阻塞并等待redis服务处理,redis处理完后请求命令后会将结果通过响应报文返回给client。如果没有pipeline那么redis就会处理完一个请求之后返回响应报文,client再发送下一个请求。
Redis的同步机制
全同步过程
- slave发送sync命令给master;
- master启动一个后台进程,将Redis中的数据快照保存到文件中;
- master将保存数据快照数据期间接收到的命令缓存起来;
- master完成文件写操作后,将文件发送给slave;
- 使用新的AOF文件替换掉旧的AOF文件;
- master将这期间收集的增量写命令发送给slave端。
注:全量同步操作完成后,后续所有写操作都是在master上进行,slave上进行读操作,虽然master也能进行读操作,但一般不会使用;为了提升性能,一般都将读操作放在slave上,因此用户的写操作需要及时扩散到slave上,以保证数据最大程度上的同步。
增量同步过程
- master收到用户的操作指令,判断是否需要传播到slave;(一般增删改才需要)
- 将操作记录追加到AOF文件;
- 将操作传播到其他slave:a)对齐zhu主从库;b)往响应缓存写入指令 ;
- 将缓存中的数据发给slave。
Redis sentinel:解决主从同步master宕机后的主从切换问题
监控:检查主从服务器是否运行正常;
提醒:通过API向管理员或者其他应用程序发送故障通知;
自动故障迁移:主从切换;
Redis 的集群原理
如何从海量的数据中尽快找到所需?
分片:按照某种规则去划分数据,分散储存在多个节点上;
常规的按照哈希划分无法实现节点的动态增减
一致性哈希算法
对2^32取模,将哈希值空间组织成虚拟的圆环
将数据key使用相同的函数hash计算出哈希值
Linux知识考点
Linux的体系结构
- 体系结构主要分为用户态(用户上层活动)和内核态
- 内核:本质是一段管理计算机硬件设备的程序
- 系统调用:内核的访问接口,是一种能再简化的操作
- 公用函数库:系统调用的组合拳
- Shell:命令解释器,可编程
查找特定文件
1 | 语法 find path [options] params |
检索文件内容
grep命令
grep [pattern] [file]
1 | grep "mooc" target* |
管道操作符 |
1 | find ~ | grep "target" |
- 前一个命令必须正确
- 右边必须能够接受标准输入流,否则数据会被抛弃
- Sed,awk,grep,cut,head,top,less,more,wc,join,sort,split等
1 | 查看包含某个字段--> 筛选出符合正则表达式的内容 |
对文件内容进行统计
awk命令
适合对列处理
1 | 语法 awk [options] 'cmd' file |
- 一次读取一行文本,按输入分隔符进行切片,切成多个组成部分
- 将切片直接保存在内建的变量中,$1,$2…($0表示行的全部)
- 支持对单个切片的判断,支持循环判断,默认分隔符为空格
1 | 文件说明: |
批量替换文件中的内容
sed命令
适合对行处理
1 | 语法:sed [option] 'sed command' filename |
- 全名stream editor,流编辑器
- 适合用于对文本的行内容进行处理
1 | sed 's/^Str/String/' replace.java |
Java底层知识:JVM
谈谈对java的理解
- 平台无关性
- GC
- 语言特性(泛型、反射、lambda表示)
- 面向对象(封装、继承、多态)
- 类库(集合库,并发库,网络库,io)
- 异常处理
Compile Once,Run anyway如何实现
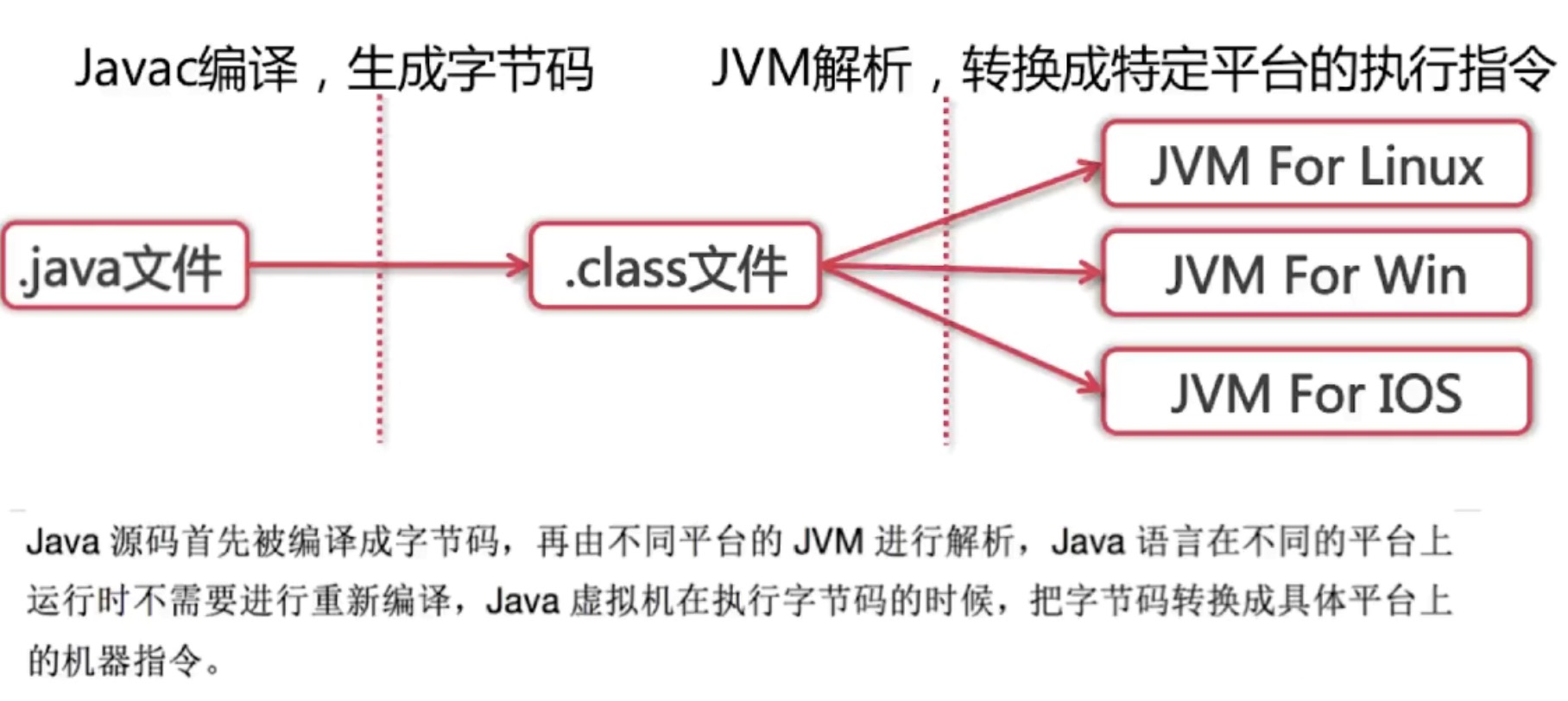
jvm如何加载.class文件
- ClassLoader: 依据特定格式,加载class文件到内存;
- Execution Engine: 对命令进行解析;
- Native Interface: 融合不同开发语言的原生库为java所用;
- Runtime data area: Jim内存空间结构模型。
反射
java反射机制在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能为java语言的反射机制。
类从编译到执行的过程
- 编译器将robot.java源文件编译为robot.class字节码文件
- ClassLoader将字节码转换为JVM中的Class<Robot>对象
- JVM利用Class<Robot>对象实例化robot对象
ClassLoader
ClassLoader在java中有着非常重要的作用,它主要工作在Class装载的加载阶段,其主要作用是从系统外部Class二进制数据流。它是java的核心组件,所有的Class都是由ClassLoader进行加载的,ClassLoader负责通过将Class文件中的二进制数据流装载进系统,然后交给JVM进行连接、初始化等操作。
- BootstrapClassLoader:c++编写,加载核心库java.*
- ExtClassLoader:java编写,加载扩展库java.ext.*
- AppClassLoader:java编写,加载程序所在目录
- 自定义ClassLoader:java编写,定制化加载
自定义ClassLoader
1 | public class MyClassLoader extends ClassLoader { |
为什么使用双亲委派机制去加载类
避免多份同样字节码加载
loadClass和forName有什么区别
类加载方式
- 隐式加载:new
- 显示加载:loadClass, forName等
类加载过程
加载–通过ClassLoader加载class文件字节码,生成class对象
链接
- 校验:检查加载的class的正确性与安全性
- 准备:为类变量分配存储空间并设置类变量初始值
- 解析:JVM将常量池内的符号引用转换为直接引用
初始化–执行类变量赋值和静态代码块
区别
- Class.forName得到的class是已经初始化完成的
- ClassLoader.loadClass得到的class是没有链接的
java内存模型
线程私有:程序计数器、虚拟机栈、本地方法栈
线程共享:MetaSpace、java堆
程序计数器:存储下一条需要执行的字节码指令,地址
虚拟机栈:
- java方法执行的内存模型
- 包含多个栈帧:局部变量表、操作栈、动态连接、返回地址
- 局部变量表:方法执行过程中的所有变量
- 操作栈:出栈、入栈
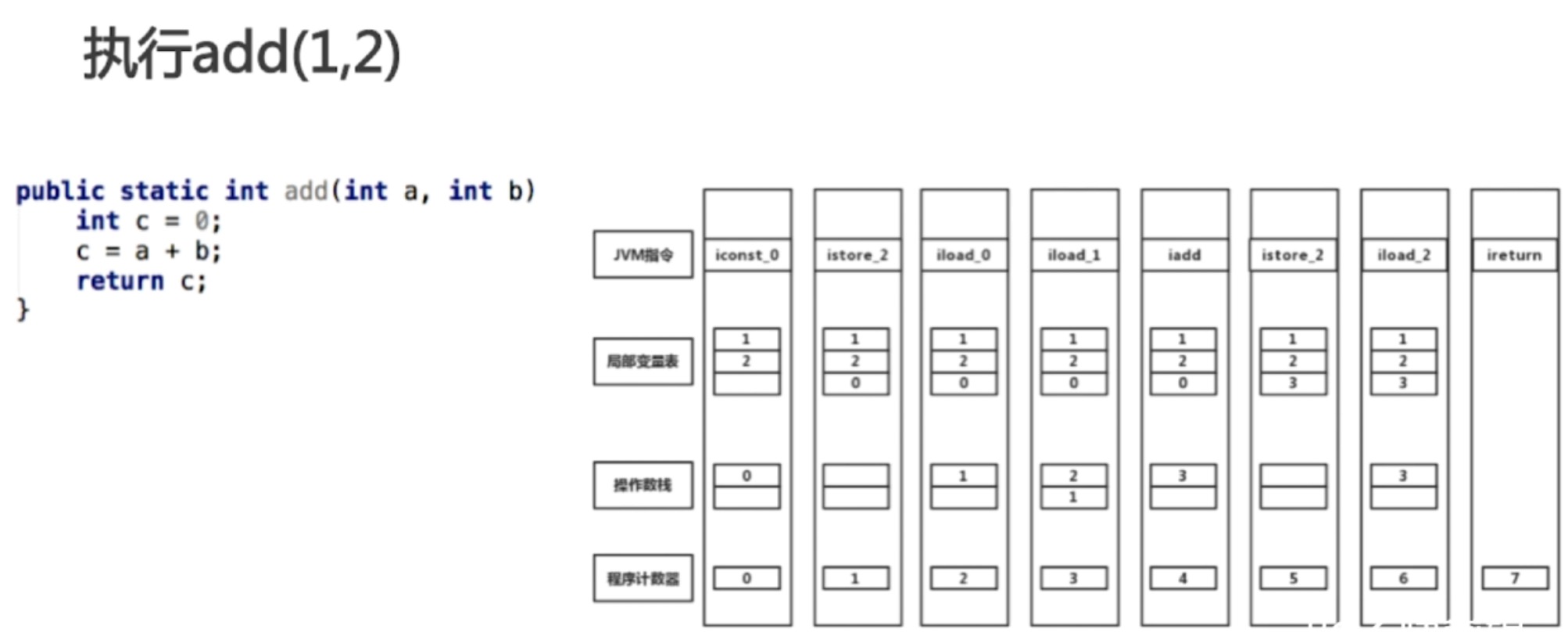
递归为什么会引起stack overflow异常
- 递归过深,栈帧数超出虚拟机栈深度
虚拟机栈过多会引发java.lang.OutOfMemoryError异常
元空间和永久代的区别
- 元空间使用本地内存,而永久代使用的是jvm内存
- 元空间没有字符串常量池

java堆
- 对象实例的分配区域
- gc管理的主要区域
JVM三大性能调优参数 -xms -xmx -xss含义
- -xss: 规定了每个线程虚拟栈(堆栈)的大小
- -xms:堆的初始值
- -xmx:堆能达到的最大值
java内存模型中的堆和栈的区别–内存分配策略
- 静态存储:编译时确定每个数据目标在运行时的存储空间需求
- 栈式存储:数据区需求在编译时未知,运行时模块入口前确定
- 堆式存储:编译时或运行时模块入口都无法确定,动态分配
java内存模型中堆和栈的区别
联系:引用对象、数组时,栈里定义变量保存堆中目标的首地址
管理方式:栈自动释放,堆需要gc
空间大小:堆比栈小
碎片相关:堆产生的碎片远小于堆
分配方式:栈支持静态和动态分配,而堆仅支持动态分配
效率:栈的效率比堆高

不同jdk版本之间的intern()方法的区别-jdk6 vs jdk6+

Java底层知识:GC相关
判定对象是否为垃圾的算法
- 引用计数法(缺点:无法检测循环引用的情况,导致内存泄漏)
- 可达性分析法
可以作为gc root的对象
- 虚拟机栈中引用的对象(栈帧中的本地变量表)
- 方法区中的常量引用的对象
- 方法区中的类静态属性引用的对象
- 本地方法栈中JNI(Native 方法)的引用对象
- 活跃线程的引用对象
垃圾回收算法
标记-清除
- 标记:从根集合进行扫描,对存活的对象进行标记
- 清除:对堆内存从头到尾进行线性遍历,回收不可达对象内存
特点:
- 碎片化
复制
- 分为对象面和空闲面
- 对象在对象面上创建
- 存活的对象被从对象面复制到空闲面
- 将对象面所有对象内存清除
特点:
- 解决碎片化
- 顺序分配内存,简单高效
- 适用于对象存活率低的场景
标记整理
- 标记:从根集合进行扫描,对存活的对象进行标记
- 清除:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。
gc的分类
- minor gc(复制)
- full gc
分代收集算法
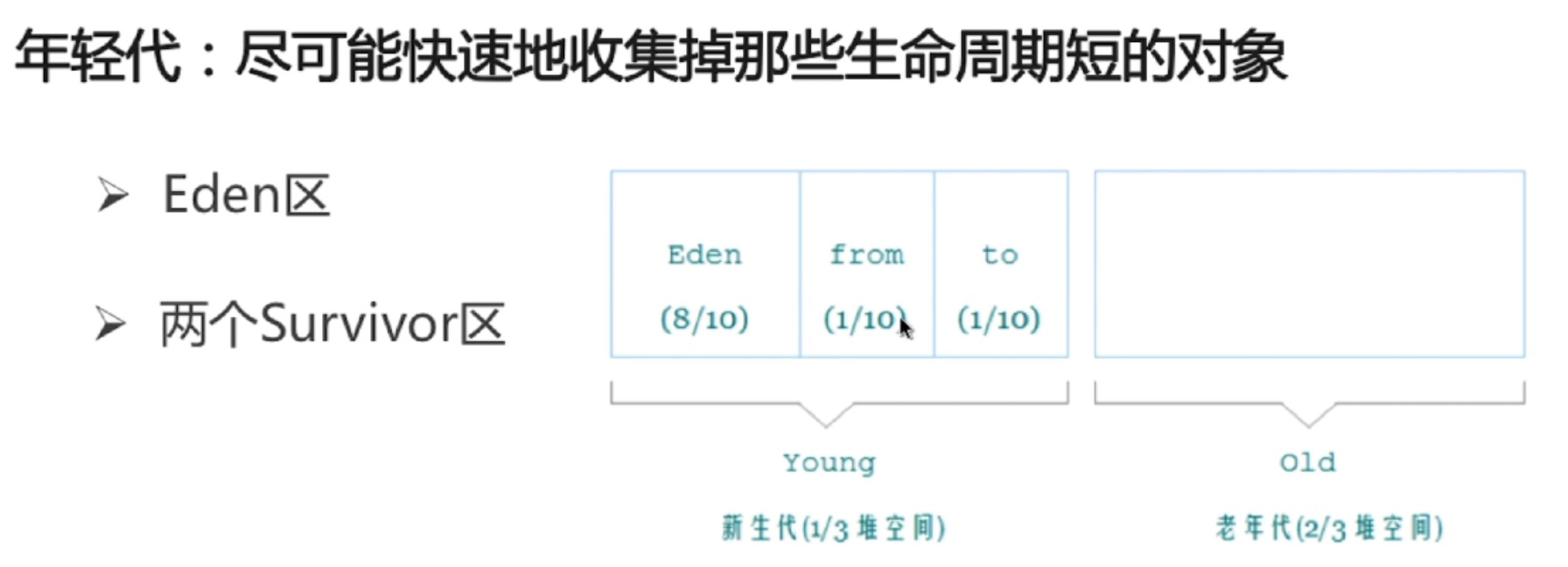
对象如何晋升到老年代
- 经历一定minor次数依然存活的对象
- Survivor区中存放不下的对象
- 新生成的大对象(-xx:+PretenuerSizeThreshold)
常用调优参数

触发full gc的条件

stop-the-world
- JVM由于要执行gc而停止了应用程序的执行;
- 任何一种gc算法中都会发生
- 多数gc优化通过减少stop-the-world发生的时间来提高性能
safepoint
- 分析过程中对象引用关系不会发生变化的点
- 产生safepoint的地方:方法调用;循环跳转;异常跳转等
- 安全点数量得适中
jvm的运行模式
- client(启动较快,轻量级)
- Server(启动较慢,重量级虚拟机,做了很多优化,运行稳定后,性能更高)
年轻代收集器
serial收集器(-xx:UseSerialGC,复制算法)
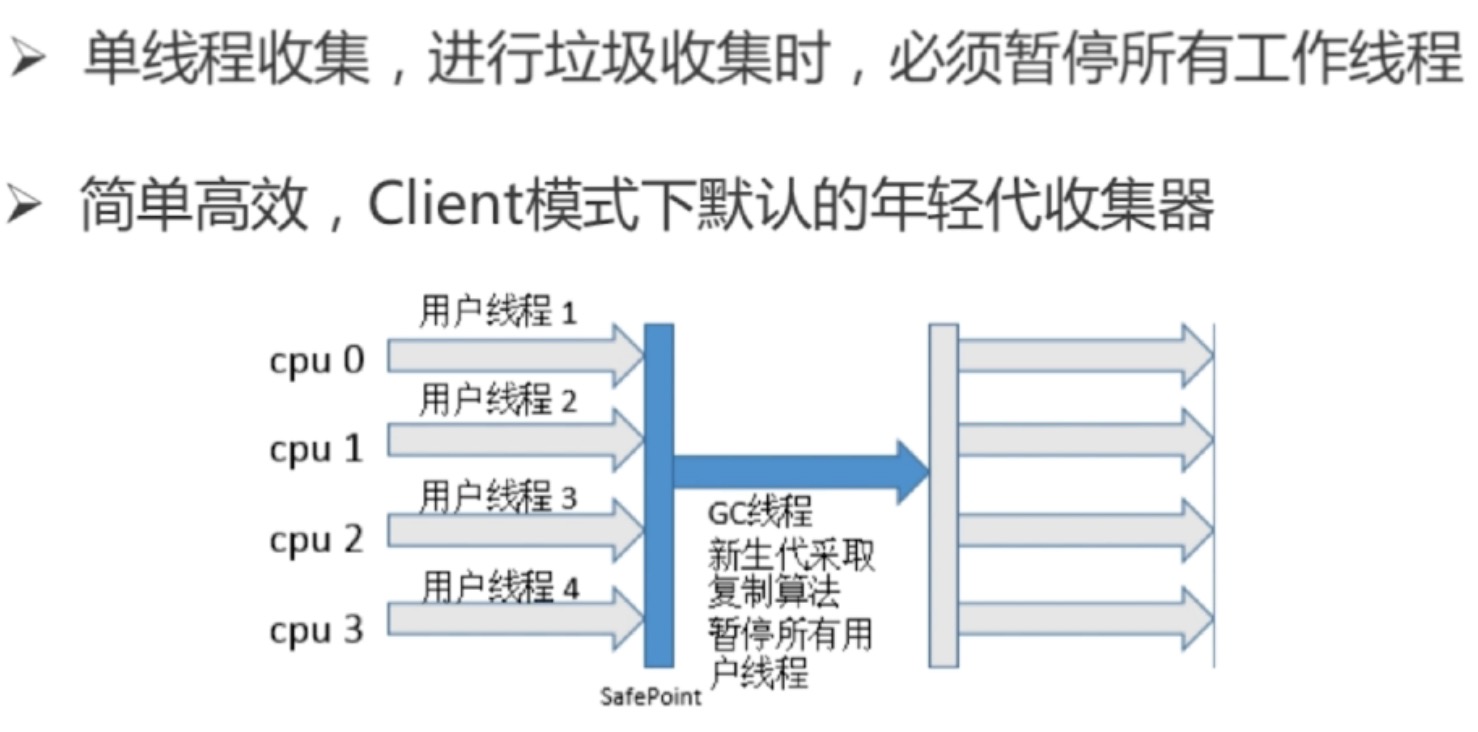
parnew收集器(-xx:+UseParNewGC,复制算法)
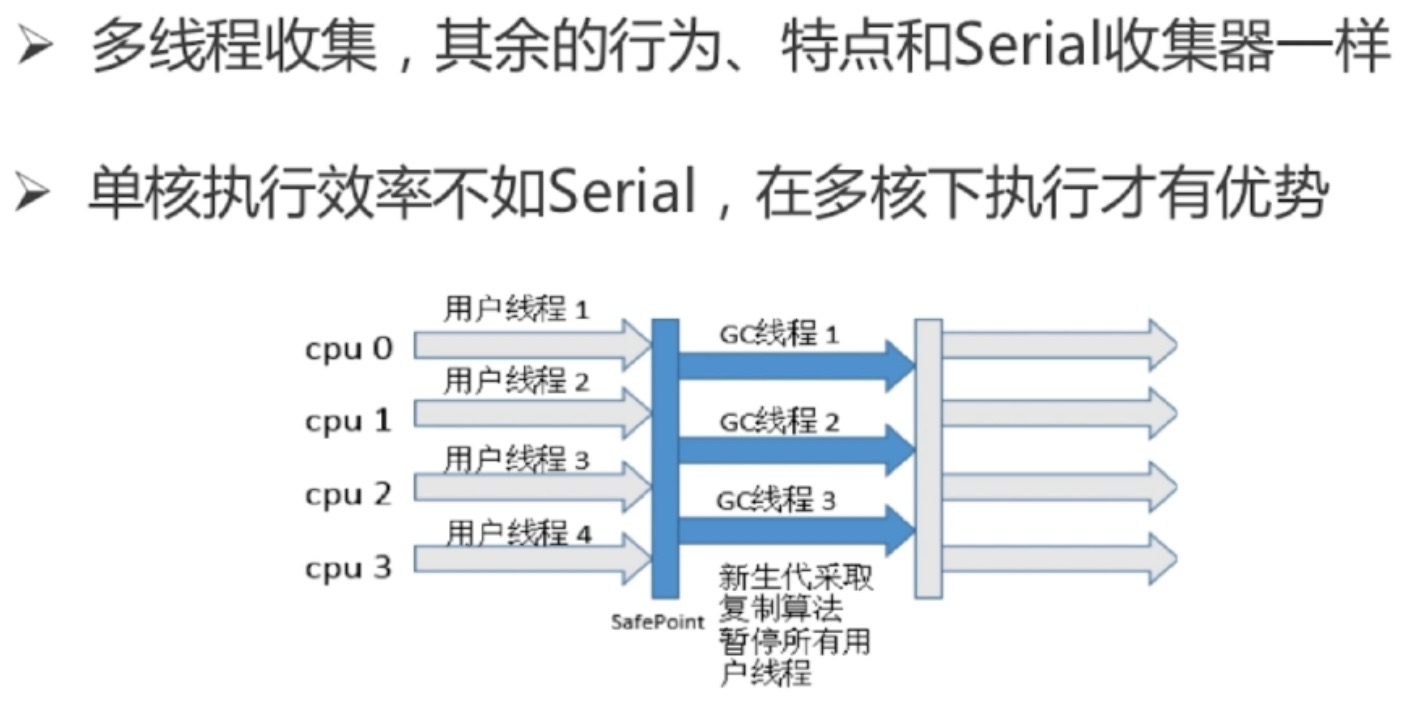
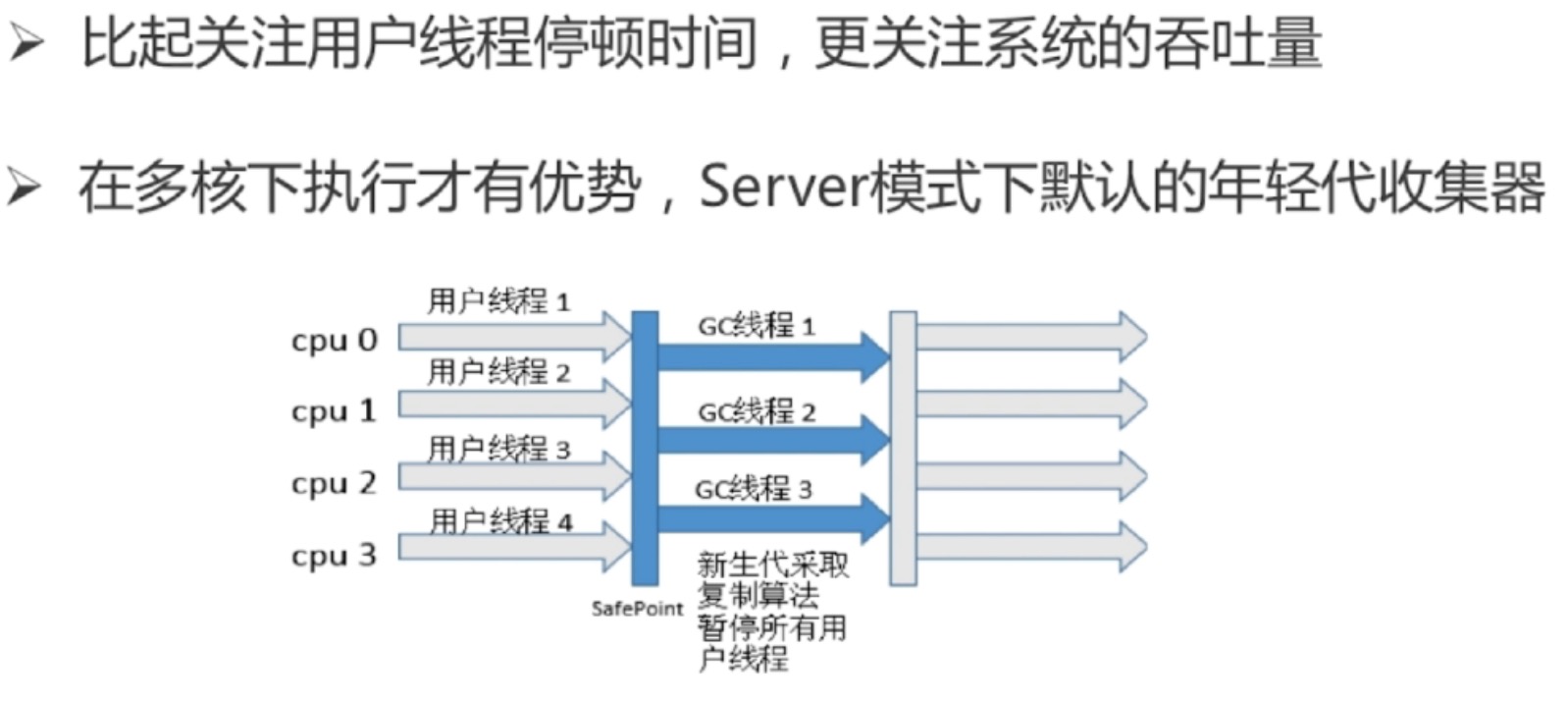
parallel scavenge收集器(-xx:+UseParallelGC,复制算法)
吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)
老年代
serial old收集器(-xx:+UseSerialOldGC,标记整理算法)
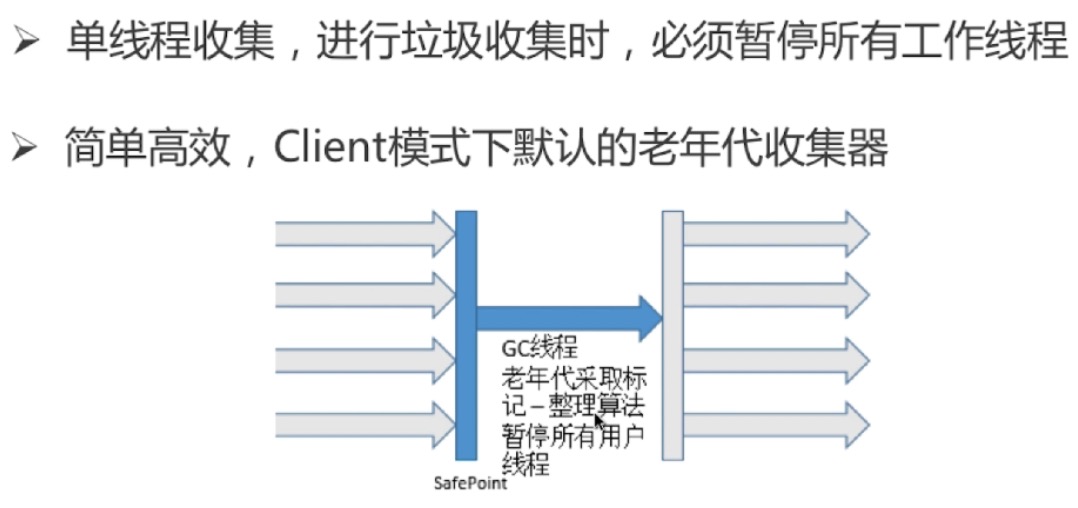
parallel old收集器(-xx:+UseParrallelOldGC,标记整理算法)
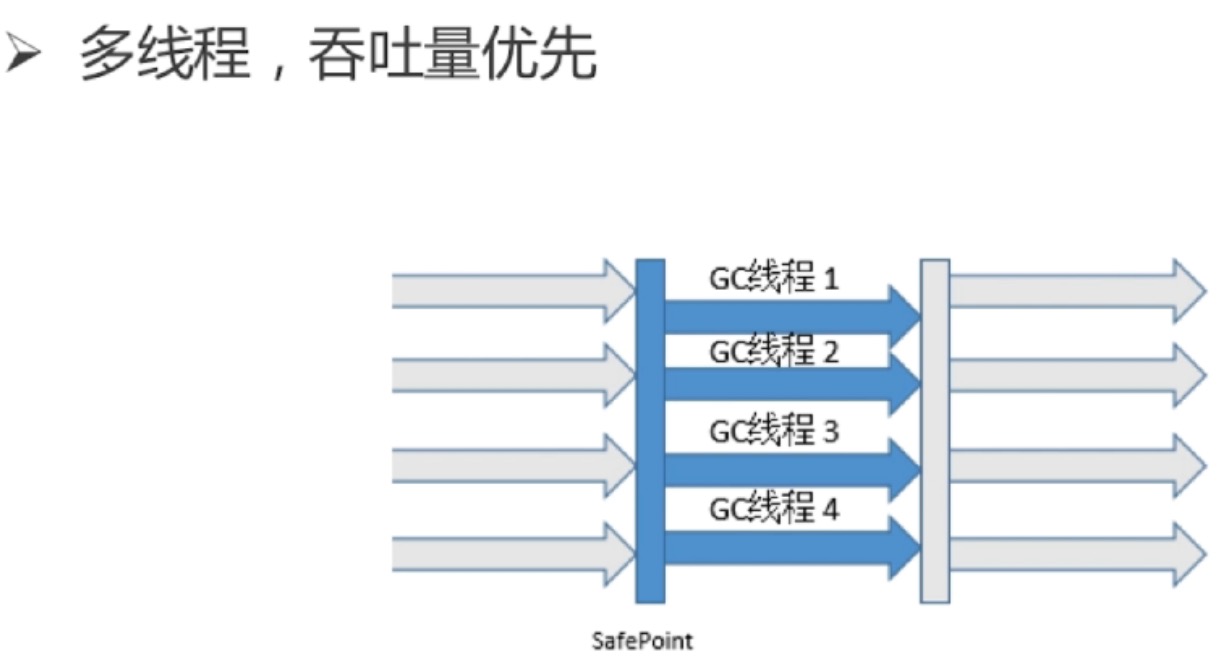
cms收集器(-xx:+UseConcMarkSweepGC,标记-清除算法)
- 初始标记:stop-the-world
- 并发标记:并发追溯标记,程序不会停顿
- 并发预清理:查找执行并发标记阶段从年轻代晋升到老年代的对象
- 重新标记:暂停虚拟机,扫描cms堆中剩余对象
- 并发清理:清理垃圾对象,程序不会停顿
- 并发重置:重置cms收集器的数据结构
g1收集器(-xx:+UseG1GC,复制+标记-整理算法)年轻代+老年代

Object的finalize()方法的作用是否与c++的析构函数作用相同
- 与c++的析构函数不同,析构函数调用确定,而它的是不确定的
- 将未被引用的对象放置于f-queue队列
- 方法执行随时可能会被终止
- 给予对象最后一次重生的机会
java中的强引用、软引用、弱引用、虚引用有什么用
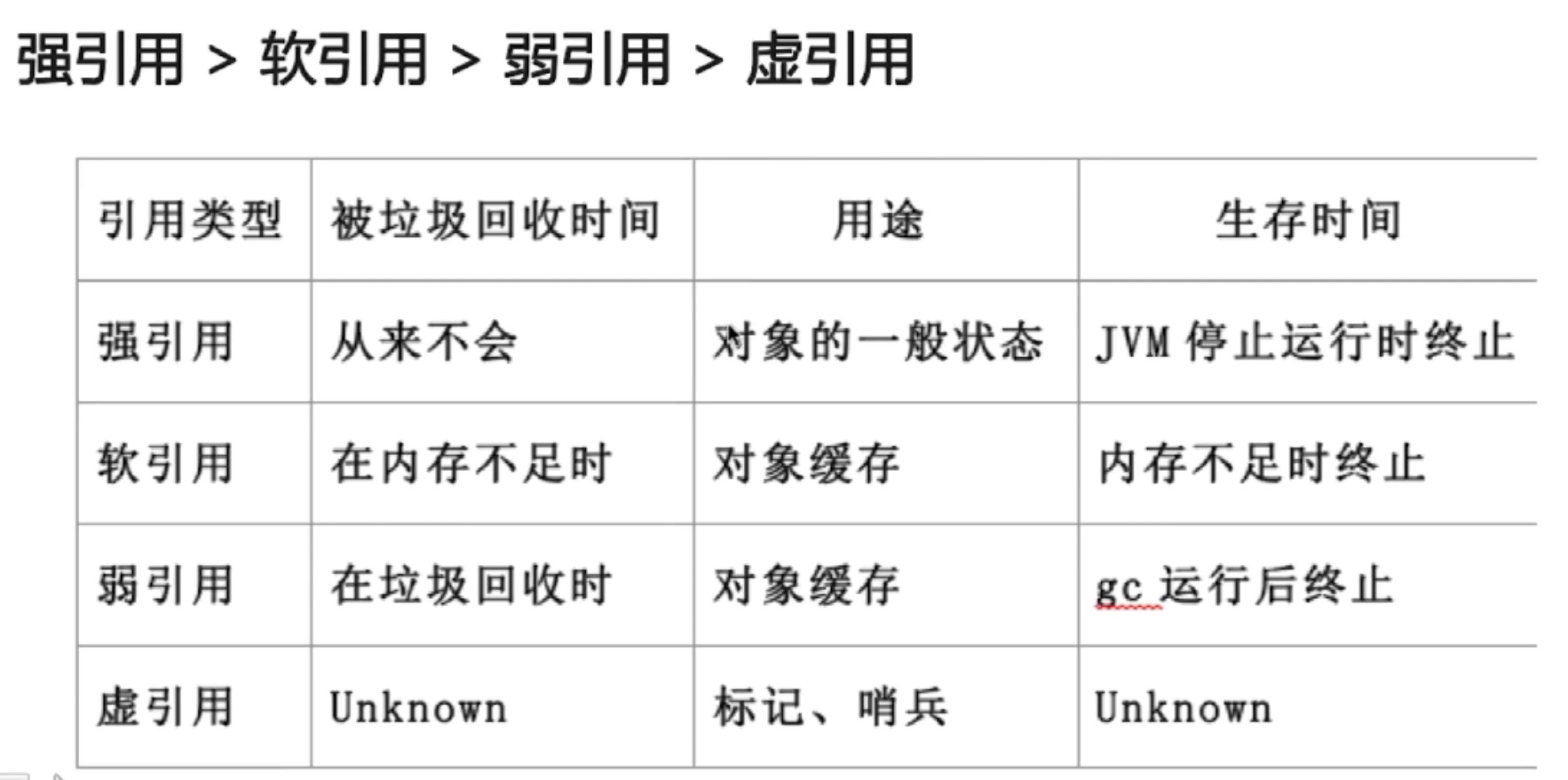
引用队列
- 无实际存储结构,存储逻辑依赖于内部节点之间的关系来表达
- 存储关联的且被gc的软引用,弱引用以及虚引用
Java多线程与并发
链接:https://blog.csdn.net/qq_37128049/article/details/90080074
Java多线程与并发-原理
链接:https://blog.csdn.net/qq_37128049/article/details/90080074
reentrantlock的condition原理
https://blog.csdn.net/zxd8080666/article/details/83214089
java常用类库与技巧
链接:https://blog.csdn.net/qq_37128049/article/details/90097438
Error和Exception的区别
Error: 程序无法处理的系统错误,编译器不做检查。
Exception: 程序可以处理的异常,捕获后可能恢复。
总结:前者是程序无法处理的错误,后者是可以处理的异常。
RuntimeException: 不可预知的,应当自行避免。空指针、数据越界
非RuntimeException: 可预知,从编译器校验的异常。
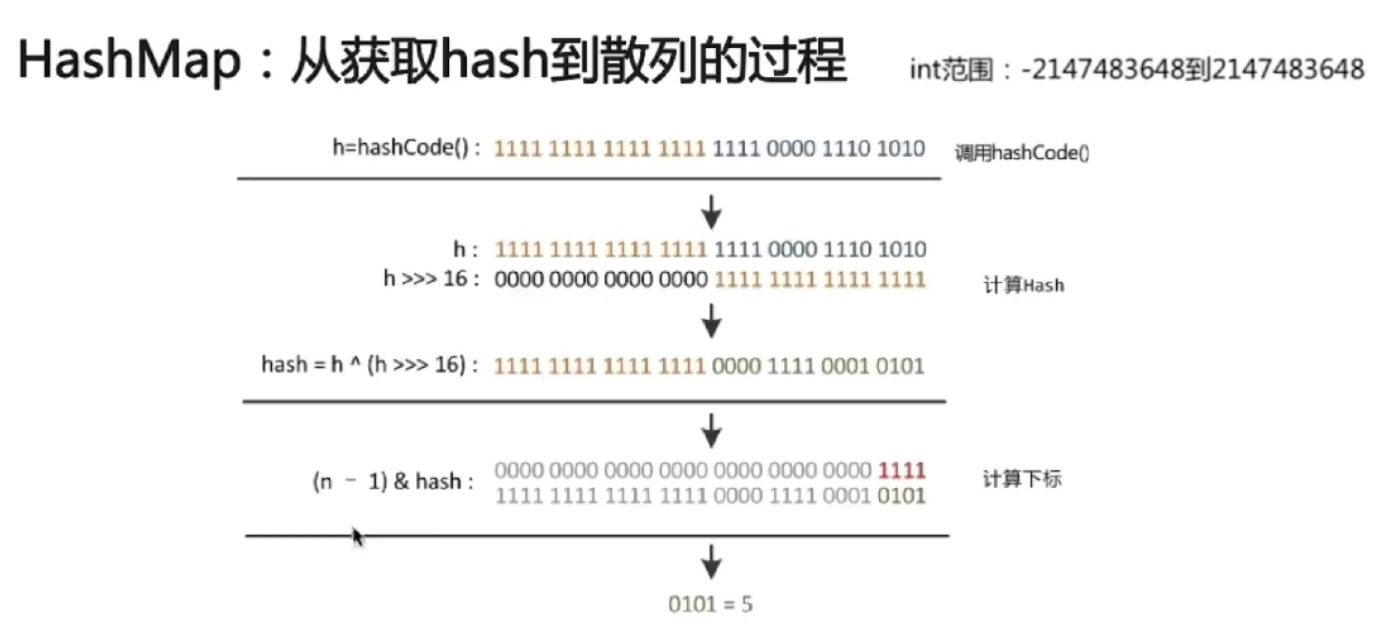
Hashmap:put方法的逻辑

hash算法
ConcurrentHashmap:别的需要注意的点
- size()方法和mapping count()方法的异同,两者计算是否准确?
- 多线程环境下如何进行扩容?
Java框架-Spring
链接:https://blog.csdn.net/qq_37128049/article/details/90140899